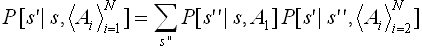История интеллектуального планирования
Интеллектуальное планирование зародилось на основе исследований
в области поиска в пространстве состояний и автоматического доказательства теорем.
STRIPS была первой системой, которая базировалась на этих двух методологиях.
Система STRIPS создавалась в качестве модуля планирования для мобильного робота
Shakey (проект Стэнфордского исследовательского
центра - SRI). Поиск решения в этой системе была основан на методологии поиска
системы GPS, а для проверки истинности предусловий действия в текущем состоянии
применялась методология доказательства теорем из системы QA3. Поэтому прежде,
чем мы перейдем к повествованию о первом планировщике (STRIPS), обратимся к
чуть более раннему периоду времени, когда были разработаны системы и методологии,
лежащие в его основе.
1957-1969гг. — GPS (General Problem
Solver)
В 1957 году была начата разработка системы, получившей название
"Универсальный решатель задач" (General Problem Solver - GPS). Эту
систему создавали сразу три автора: Алан Ньюэл, Дж. Шоу и Герберт Саймон. Первая
публикация по результатам работы появилась лишь 1959 году [Newell
et al., 1959].
Название "Универсальный решатель задач" обусловлено
тем фактом, что это была первая система для решения задач (problem-solving system),
в которой общие методы решения задач были отделены от знаний, определяющих конкретную
задачу. Часть программы, осуществлявшая поиск решения, не обладала информацией
о конкретном виде задачи, с которой она работала. Специфичные для конкретной
задачи знания организовывались в отдельные структуры: объекты и операторы
для преобразования объектов. Задача для системы GPS ставилась в виде пары, состоящей
из начального объекта и желаемого объекта, в который начальный объект должен
быть преобразован.
Методология, использованная в GPS, отличается от стандартных
методов поиска в пространстве состояний тем, что она выбирает путь, по которому
продолжить поиск. Т.е. система пытается искать решение в первую очередь в "наиболее
перспективных" ветвях поиска. Такая методология была названа "анализ
средств и целей" (means-ends analysis). Ее суть заключалась в том,
что сначала отыскивалось различие (difference) между текущим объектом
и объектом, который мы хотим получить. Это различие относилось к одному из ряда
классов различий. С каждым классом был сопоставлен набор действий,
способных уменьшить различие между текущим и целевым объектами.
На каждом шаге поиска GPS искал различие объектов и выбирал один
из релевантных операторов, который и пытался затем применить к текущему объекту.
Поиск подходящей последовательности операторов выполнялся в глубину до тех пор,
пока операторы оказывались применимы, а ветвь поиска "выглядела перспективной".
Если ветвь поиска была бесперспективной, то выполнялся откат. Важной особенностью
анализа средств и целей является то, что всегда выбирается релевантный оператор,
уменьшающий различие объектов, даже если он и не применим к текущему объекту.
Вместо того чтобы отказаться от неприменимого к текущему объекту оператора,
GPS пытался преобразовать текущий объект в объект, пригодный для применения
выбранного оператора. Применение такой стратегии привело к появлению рекурсивной,
целеориентированной процедуры, которая фиксирует историю поиска в графе с частично
проработанными узлами.
Несмотря на то, что в качестве объекта могла выступать модель
мира, а в качестве оператора - действие, задача планирования перед системой
GPS не ставилась. Такой вариант использования GPS был осуществлен значительно
позднее, когда была разработана система STRIPS, упомянутая ранее. Ниже мы подробно
рассмотрим, как это было реализовано.
1969г. — QA3 (Question Answering system,
version 3)
В июле 1969 года Кордел Грин (Cordell Green) представил публике
свою диссертационную работу [Green C., 1969a], посвященную
вопросно-ответной системе, которая называлась QA3. Система QA3 хотя и была вопросно-ответной
системой, однако содержала в себе еще и механизмы для решения задач. В частности,
эта система могла отвечать на вопросы такого типа: "Существует ли последовательность
действий такая, что объект object1 окажется в комнате room4,
если изначально он находится в комнате room2?" Такая формулировка
вопроса является, по сути, постановкой задачи планирования. Но так как целю
системы QA3 были все-таки ответы на вопросы, а не решение задач, да и реализация
механизма решения задач имела множество ограничений, эта система не претендует
на звание первого планировщика.
Работа системы QA3 основывалась на механизме доказательства
теорем методом резолюций. Т.е. вопросы к системе формулировались в виде
формул исчисления предикатов первого порядка (first-order logic). В такой же
форме хранились и знания. Формула-вопрос рассматривалась как теорема, которую
нужно доказать, основываясь на формулах-знаниях. Система выдавала результат,
в котором содержалась информация о том, нашла ли система ответ, и множество
значений для переменных из формулы-вопроса, которые и являлись ответом. Например,
вопрос можно было сформулировать так "Кто родился в 1831 году?" Этот
вопрос можно переформулировать, например следующим образом: "Существует
ли z такое, что родился z в 1831 году?". Такая формулировка имеет прямое
отражение в формулу исчисления предикатов первого порядка. Система QA3 ищет
ответ на этот вопрос-формулу, проверяя выводимость формулы-вопроса из формул-знаний
системы. При выводе определяется подстановка для z, которая и будет ответом.
Например, система может вывести что z="Шишкин Иван Иванович - известный
русский живописец".
Кратко рассмотрим, как же система QA3 отвечала на вопросы о последовательностях
действий. Чуть ранее, в мае 1969 года в трудах 1-ой Международной конференции
по искусственному интеллекту (IJCAI'69) Грин описал [Green
C., 1969b] технологию, как можно решать задачу о существовании целенаправленной
последовательности действий при помощи доказательства теорем методом резолюций.
Он нашел способ описания состояний (state) и преобразований состояний (state
transformation) в рамках исчисления предикатов. Рассмотрим на примере, как он
это сделал.
Факты о мире, на вопросы о котором отвечает система, выражались
в форме предложений логики исчисления предикатов первого порядка (далее просто,
логики первого порядка). Вопросы формулировались в виде утверждений, которые
необходимо доказать. Предполагалось, что в любой момент времени мир находится
в некотором состоянии. Будем обозначать состояния буквой s с индексом внизу,
например, s7. Состояния описываются при помощи предикатов. Например,
если предикат AT(object1, room4, s1) истинен,
то это значит, что в состоянии s1 объект object1 находится
в комнате room4. Множество предикатов, связанных с одним состоянием
и будут полностью определять состояние. Пусть вышеозначенный предикат будет
аксиомой A1.
A1: AT(object1, room4,
s1)
Действия и последовательности действий осуществляют изменения
состояний. Действие может быть представлено как функция, отражающая состояние
в новое состояние (достигаемое в результате выполнения действия). Аксиомы, описывающие
эффект действия имеют следующую форму:
("s)
[ P(s) —> Q(f(s)) ]
где
s - переменная, обозначающая состояние (state variable),
P - предикат, описывающий состояние до применения действия,
Q - предикат, описывающий состояние после применения действия,
f - функция (соответствующая некоторому действию), которая отражает некоторое
состояние в новое состояние (достигаемое посредством выполнения действия).
В качестве примера рассмотрим аксиому, описывающую то, что предмет
object1 может быть перемещен из комнаты room4 в комнату room2.
A2: ("s)
[ AT(object1, room4, s) —> AT(object1,
room2, transfer(object1, room4, room2,
s)) ]
Здесь функция transfer(object1, room4,
room2, s) соответствует действию перемещения предмета object1
из room4 в room2.
Теперь рассмотрим вопрос "существует ли последовательность
действий такая, что предмет object1 будет находиться в room2?"
Тот же вопрос можно выразить следующей фразой, "существует ли состояние,
возможно полученное в результате применения действий-функций, такое, что предмет
object1 будет находиться в room2?" Этот вопрос может
быть записан в виде утверждения в логике первого порядка: ($s)
AT(object1, room2, s). Это утверждение может быть доказано
на основании аксиом A1 и A2 при помощи метода резолюций. И в качестве ответа
будет выступать подстановка s=transfer(object1, room4,
room2, s1).
Последовательность действий может быть выражена в виде композиции
функций. Естественный порядок вычисления функций (от наиболее вложенных к наиболее
внешним) определит последовательность, а сами функции определяют действия.
Например, пусть у нас есть еще одна аксиома:
A3: ("s)
[ AT(object1, room2, s) —> AT(object1,
room9, transfer(object1, room2, room9,
s)) ].
Тогда последовательность действий, перемещающая предмет object1
из помещения room4 в room9, начиная с состояния s1,
может быть записана следующим образом через композицию функций: transfer(object1,
room2, room9, transfer(object1, room4,
room2, s1)).
В той же работе Грин приводит расширенный вариант формулировки
задачи. В предыдущем варианте мы не могли указать начальное состояние как параметр
поиска. Грин предложил более гибкий вариант формулировки, в которой функция-действие
отражает не предикат до применения действия в предикат после применения действия,
а состояние в новое состояние. В качестве аргументов эта функция получает действие
и состояние, к которому действие применяется, а на выходе формируется новое
состояние - newState=function(action, oldState). Используя такой формализм,
мы можем внести начальное состояние мира в постановку задачи. Например, задача
может быть сформулирована так, "существует ли последовательность действий
x, которая отражает состояние s0 в состояние, в котором истинен предикат
Q?" Или, говоря математическим языком, ($x)
Q(f(x, s0)). Например, ($x) AT(object1,
room2, f(x, s0)).
Кроме этого Грин предложил использовать (при необходимости) аксиомы,
не изменяющие состояние. Эти аксиомы являлись, по сути, импликацией в рамках
состояния и могли служить, например, для отражения зависимости между объектами.
Полезность таких аксиом можно продемонстрировать следующим утверждением: ("
x, y, z, s) [ LEFT(x, y, s) & LEFT(y, z, s) —> LEFT(x, z, s) ].
Т.е. Если объект x находится левее y, а объект y находится левее z, то
и x находится левее z в любом состоянии.
Еще одним полезным расширением, предложенным Грином, являются
условные эффекты. Это расширение реализовывалось при помощи функции select,
которая обладала четырьмя параметрами. Если первые два параметра оказывались
равны, то функция возвращала третий параметр, иначе она возвращала четвертый.
Такую функцию можно, например, реализовать через пару аксиом:
ACE1: (" w, x,
y, z) [ w = x —> select(w, x, y, z) = y ]
ACE2: (" w, x,
y, z) [ ¬(w = x) —> select(w, x, y, z) = z ]
Тогда условный эффект можно было выразить при помощи перехода
в то или иное состояние в зависимости от некоторого условия. Например, выражение
для получения состояния по условию можно записать так: s = select(a, b, f(x,
s0), f(y, s0), т.е. в зависимости от равенства a и b будет
выполнено действие x или y.
Не смотря на возможность решать некоторые задачи планирования,
система не получила развития, как планировщик. Система STRIPS использовала только
часть методов QA3, а именно, доказательство теорем методом резолюций.
1971г. — STRIPS
Первой системой, которая создавалась именно для решения задачи
планирования, была система STRIPS (STanford Research Institute Problem Solver).
Разработана система была в 1971 году двумя исследователями - Ричардом Файксом
и Нильсом Нильсоном. Описание системы опубликовано в трудах 2-ой международной
конференции по искусственному интеллекту (IJCAI'71) [Fikes,
Nilsson, 1971].
Файкс и Нильсон сформулировали задачу планирования такой, какова
она и по сей день. Задача планировщика найти такую последовательность действий,
которая преобразует начальное состояние в такое состояние, в котором достигается
заранее заданное целевое условие (В оригинальной статье используются понятия
"модель мира" для обозначения состояния и "оператор" для
обозначения действия. Мы будем придерживаться современной терминологии.). Состояние
представляется множеством формул логики первого порядка (в оригинальной статье,
well-formed formulas (wffs)). Цель также описывается формулой. Действия описываются
в виде специальных конструкций, которые мы рассмотрим ниже.
STRIPS пользуется методологией доказательства теорем только в
рамках одного заданного состояния для получения ответа на вопросы "какие
действия применимы" и "достигнуты ли целевые условия" (в отличие
от QA3, где методы доказательства теорем использовались и для перехода из состояния
в состояние). В STRIPS поиск в пространстве состояний осуществляется по аналогии
с системой GPS, а именно, используется стратегия "анализ средств и целей".
Формально, постановка задачи в STRIPS включает три составляющие:
начальное состояние, множество действий и целевую формулу. Как уже было сказано,
состояния описываются множеством формул. Например, то, что объект obj1
находится в комнате room2, можно выразить следующей формулой: At(obj1,
room2). Кроме таких "описательных" аксиом, можно включать
аксиомы-правила, наподобие тех, что использовал Грин. Например, можно написать,
что если объект находится в комнате room2, то он не находится ни
в какой другой комнате. Формально это можно представить так: ("
x, y, z) [ At(x, y) & ¬(y = z) —> ¬At(x, z) ]. Если формула
является литералом, то это должен быть позитивный литерал (без знака отрицания).
Все атомарные формулы во множестве формул, описывающих состояние, должны быть
означены (ground), т.е. не иметь свободных переменных. Утверждения,
не входящие в число формул, описывающих состояние, и не являющиеся их логическим
следствием, считаются ложными. Это последнее допущение в литературе называют
допущение о замкнутости мира (closed-world assumption).
Действия группируются в классы действий, называемые схемами
действий (в оригинальной статье, соответственно, схемы операторов). Такой
подход позволил существенно сократить описание задачи. Рассмотрим, например,
действие goto, перемещающее робота из одной комнаты в другую (напомним, что
STRIPS создавался для управления роботом). Существует множество таких действий
для каждой пары сообщающихся комнат. Было бы удобно сгруппировать все такие
действия в рамках одной параметризованной схемы goto(x, y), где параметр x -
обозначает начальное месторасположение робота, а y - конечное. Конкретные действия
получаются из описания схемы путем подстановки конкретных сущностей (констант)
вместо параметров. Применять можно только конкретизированные схемы действий,
т.е. сами действия.
Введение понятия схемы было необходимо для задачи управления
роботом, т.к. в этой задаче было также действие перемещения между двумя точками
в комнате, а точек могло быть очень много. Без схем, описание задачи было бы
очень большим. С тех пор понятие схемы действия вошло в практику планирования
как постоянный компонент. В настоящее время все планировщики прибегают именно
к такой (параметризованной) форме описания действий.
Описание каждой схемы действия (а, соответственно, и самого действия)
состоит из двух основных частей: описания эффекта действия и описания условий,
при которых действие применимо. Эффект действия определяется через два списка:
список формул, которые добавляются к состоянию, и список формул, которые удаляются
из состояния, т.к. становятся ложными в результате применения действия. Отметим,
что если формула из списка добавления уже присутствует в текущем состоянии (состоянии,
к которому применяется действие), то эта формула не будет добавлена вторично.
Аналогично, если формула из списка удаления уже отсутствует в текущем состоянии,
то ее удаление игнорируется. Все формулы, которые не упоминаются в эффекте,
остаются неизменными в новом состоянии. Это последнее утверждение в литературе
называют STRIPS-допущением (STRIPS assumption).
Условия применимости действия, называемые также предусловием
(precondition), задаются при помощи одной формулы. Для того, чтоб узнать применимо
ли действие в некотором заданном состоянии, мы должны проверить истинность предусловия,
т.е. доказать, что предусловие является логическим следствием множества аксиом
данного состояния. Если предусловие истинно, то действие применимо.
Важно отметить, что в схеме действия мы имеем дело со схемами
формул, т.к. параметры действия могут фигурировать и в формулах. Например, у
вышеупомянутой схемы goto(x,y) может быть следующее предусловие Robot_at(x).
Конкретизация предусловия может происходить в процессе доказательства его истинности
в некотором состоянии. Сам процесс доказательства предлагает подстановку для
данного параметра такую, чтобы сделать формулу истинной. Следует различать параметры
схемы действия и связанные переменные формулы (квантифицированные переменные),
и этот момент нужно учитывать при доказательстве истинности формул.
Фактически, с введением параметров в формулы изменения в подходе
к доказательству теорем коснутся только двух аспектов. Во-первых, потребуется
изменение алгоритма унификации. Так для связанных переменных допустимы следующие
подстановки: переменные, константы, параметры и функциональные термы, не содержащие
переменных. Для параметров же допустимы такие подстановки: константы, параметры
и функциональные термы, не содержащие сколемовых функций, переменных и параметров.
Во-вторых, один и тот же параметр может фигурировать в нескольких формулах и
надо следить, чтобы подстановка затрагивала именно все формулы. Т.е. в данном
случае это будет не набор одноименных сущностей (как это было бы с переменными),
а одна сущность.
Приведем пример того, как схема действия может быть описана в
STRIPS. Рассмотрим схему действия Fly - перелет самолета из одного аэропорта
в другой.
fly (p, from, to)
precondition = At(p, from) & Plane(p) & Airport(from) &
Airport(to)
delete list = { At(p, from) }
add list = { At(p, to) }.
Здесь fly - имя схемы действия, за которым следует список параметров
схемы (p, from, to). Следующая строка описывает предусловие. Для того, чтобы
действие перелета совершилось, нужно чтобы самолет находился в аэропорту отправления.
В предусловии мы указываем, что p - это самолет (Plane(p)), а from и to - аэропорты
(Airport(from) & Airport(to)), и что самолет находится в пункте отправления
(At(p, from)). В следующей строке описан список удаления. Он состоит всего из
одного элемента - At(p, from). Удаляя эту формулу из состояния, мы получим эффект
того, что самолет больше не находится в пункте отправления. И наконец, последняя
строка описывает список добавления, который также состоит из одной формулы -
At(p, to) - постулирующей то, что самолет окажется в пункте назначения после
того, как действие будет выполнено.
Для осуществления поиска плана была использована стратегия GPS,
которая определяет "различие" между текущим состоянием и целью и находит
действия, способные уменьшить это различие. После того, как подходящее действие
найдено, мы решаем подзадачу порождения состояния, к которому данное действие
применимо. Если такое состояние обнаруживается, то действие применяется и изначальная
цель рассматривается вновь уже в новом состоянии. Когда действие признано подходящим
(релевантным), мы еще не знаем, где оно появится в конечном плане. Т.е. может
оказаться, что перед ним должны стоять другие действия, которые делают возможным
выполнение данного действия. После него также могут оказаться действия, которые
обеспечивают выполнение всей цели (ведь одно действие служит уменьшению различия,
а не обязательно достижению цели сразу).
STRIPS начинает работу с попытки доказать, что цель является
следствием множества формул, описывающих начальное состояние. Если цель следует
из начального состояния, то задача решена. В противном случае незавершенное
доказательство теоремы (то, что пока не удалось доказать) рассматривается
в качестве различия между состоянием и целью. Затем выполняется поиск схемы
действия, эффект которой может добавить (или удалить) такую формулу, что доказательство
будет продолжено. Здесь может потребоваться частичная или полная конкретизация
формулы эффекта. Подходящих схем действий может быть несколько, поэтому будут
формироваться ветви поиска, в каждой из которых прорабатывается один способ.
После того, как схема действия выбрана, ее предусловие (возможно частично конкретизированное)
рассматривается в качестве новой подцели. При попытке доказать это предусловие
выполняется конкретизация предусловия. Т.е. процесс доказательства ищет такие
подстановки для параметров формулы, чтобы сделать эту формулу истинной в текущем
состоянии. Если такая подстановка находится, то схема действия конкретизируется
и действие применяется, иначе в процессе доказательства вновь формируется различие
и процесс повторяется.
Файкс и Нильсон отмечают, что интересно было бы попробовать применять
не полностью конкретизированные действия. Тогда бы получались не состояния,
а схемы состояний. Но авторы не стали сами пробовать такой подход.
Авторы также отмечают, что в списке удалений иногда удобно записывать
не сами формулы, а некоторые их прототипы. Например, одним из эффектов действия
goto для робота должно быть удаление информации о том, куда робот был направлен
лицом, даже если эта информация не указывается в качестве параметра схемы действия.
В этом случае в список удаления можно поместить запись вида facing($), смысл
которого следующий: "всякая формула соответствующая этому прототипу (независимо
от значения $) должна быть удалена".
Коль скоро мы имеем дело со сложными формулами, мы должны учитывать
следующий момент, связанный с удалением формул. Если мы удаляем некоторую формулу,
мы должны будем также удалить и все формулы, которые были выведены на основании
данной.
Иерархия целей, подцелей и состояний, полученных в процессе поиска,
называется деревом поиска (search tree). Как уже упоминалось ветвление
обусловлено тем, что различие между целью и состоянием может быть уменьшено
несколькими способами. Каждый узел дерева поиска представляет собой пару (состояние,
список целей). Фактически в узле описывается текущее состояние и стек целей
(подцелей), которые нужно достичь. Всякий раз, когда STRIPS порождает очередной
узел, он проверяет, достигается ли первая цель списка целей нового
узла в состоянии, означенном в новом узле. Если это так, и целью является
предусловие некоторого действия, то действие применяется (напомним, что предусловие
- это одна формула), после чего порождается новый узел с новым состоянием и
тем же самым списком целей, в котором отсутствует первая цель (мы ее уже достигли).
Если же первая цель не достигается в состоянии, означенном в узле, то на основании
различия отыскивается подходящее действие и формируется новый узел путем добавления
предусловия этого действия. STRIPS пользуется эвристикой для выбора, какой узел
рассматривать следующим. Эвристическая функция оценивает такие факторы, как
количество оставшихся целей в списке целей и количество и виды предикатов в
целевых формулах.
Т.к. описание модели мира может быть достаточно большим в задаче
с роботом, не очень выгодно хранить копии модели мира в каждом узле по двум
причинам. Во-первых, одна и та же модель мира может использоваться в описании
нескольких узлов. Во-вторых, большинство утверждений в описании модели мира
остаются неизменными. Лишь небольшое их число изменяется в ответ на воздействие
робота. Поэтому было предложено следующее решение по организации памяти. Все
формулы всех моделей мира хранятся в единой структуре памяти. В узлах же хранятся
только флаги, какие формулы стали истинны, а какие ложны по сравнению с начальным
состоянием.
В последствии STRIPS подвергался обширной критике и за подход
к описанию мира и действий, и за алгоритм поиска.
1972г. — STRIPS + MACROP
Уже в следующем году те же авторы совместно с Питером Хартом
представили доработку своей системы. В своей статье [Fikes,
Hart, Nilsson, 1972] они описывают механизм для обобщения планов, порожденных
STRIPS. Обобщенные планы хранились в специальных треугольных таблицах
(triangle tables) и использовались как своеобразные "макрооператоры"
для повторного применения в других задачах планирования, а также для мониторинга
исполнения плана. Получение и сохранение обобщенных планов являлось некоторого
рода формой обучения, которое позволяло уменьшить время, необходимое на поиск
плана в схожих задачах.
В своем первозданном виде STRIPS выдает в качестве результата
полностью конкретизированный план. Ключевым моментом доработки к STRIPS стало
обобщение плана путем замены констант параметрами. Другими словами, конкретный
план становится схемой плана (plan schema) или макрооператором
(macro operator), который подобен примитивным схемам действий, заданным в задаче
изначально. Сначала мы рассмотрим треугольные таблицы, в которых такие макрооператоры
хранятся, а затем перейдем к рассмотрению способа получения и использования
макрооператоров.
Разумно сохранять план так, чтобы потом можно было воспользоваться
любым фрагментом этого плана. Для этого необходимо знать предусловия и эффекты
всех действий в плане. Вообще мы должны быть способны установить роль каждого
действия в плане: какие эффекты главные, а какие побочные, и почему эти эффекты
необходимы в плане. Чтобы решить эти задачи, было принято решение хранить планы
в специальных таблицах, названных треугольными.
Треугольная таблица получается из прямоугольной, если провести
диагональ из верхнего левого угла в нижний правый и из получившихся двух треугольников
отбросить верхний треугольник (диагональные элементы входят в нижний треугольник).
Оставшийся треугольник и будет треугольной таблицей. Строки и колонки треугольной
таблицы соответствуют действиям в плане (или схемам действий в обобщенном варианте
таблицы).
Треугольная таблица имеет следующий общий вид (здесь представлена
таблица для плана из четырех действий).
| 1 |
Precondition1 |
Action1 |
Action2 |
Action3 |
Action4 |
| 2 |
Precondition2 |
Add1 |
| 3 |
Precondition3 |
Add1/2 |
Add2 |
| 4 |
Precondition4 |
Add1/2,3 |
Add2/3 |
Add3 |
| 5 |
|
Add1/2,3,4 |
Add2/3,4 |
Add3/4 |
Add4 |
| |
0 |
1 |
2 |
3 |
4 |
Колонки таблицы, за исключением нулевой, помечены именами действий
в плане (в примере, Action1,..., Action4). Ячейка с индексами
[i, j] содержит такие формулы, которые были добавлены j-ым действием и оставались
истинными к моменту применения i-ого действия. Например, запись Add1/2,3
означает те формулы, которые были добавлены действием Action1 и не
были потом удалены действиями Action2 и Action3. Т.к.
ячейки i-ой строки (за исключением самой левой ячейки - нулевая колонка) содержат
формулы, добавленные одним из (i-1)-ым действием и не удаленные другими действиями
из этого диапазона, мы можем говорить, что объединение ячеек i-ой строки определяет
список добавления (add list) фрагмента плана, содержащего первые (i-1) действий.
Т.е. это список добавления последовательности действий Action1, ...,
Actioni-1. Объединение ячеек нижней строки таблицы определяет список
добавления всего плана. Будем обозначать список добавления первых j действий
плана следующим образом: Add1,...,j.
Нулевая колонка содержит формулы из начального состояния, которые
были использованы при доказательстве предусловий плана. Так нулевая ячейка в
i-ой строке содержит те формулы из начального состояния, которые потребовались
при доказательстве предусловия i-ого действия. Вообще для доказательства предусловия
i-ого действия достаточно формул из i-ой строки треугольной таблицы. Часть формул
поставляются предшествующими действиями (формулы в ячейках с индексом больше
нуля), а часть берется из начального состояния. Вот эта вторая часть и указывается
в нулевой колонке. Отметим, что для доказательства предусловия i-ого действия
может использоваться часть формул из ячеек с индексом больше нуля и
должны использоваться все формулы из нулевой ячейки. Формулы, которые
участвуют в доказательстве, называют помеченными (marked).
Рассмотрим теперь предусловия действий плана, начиная с i-ого
и заканчивая последним действием. Эта последовательность действий (от i и до
конца) применима, если текущее состояние уже содержит те предусловия действий
последовательности, которые не выводятся в самой последовательности. Для работы
с этими предусловиями вводится понятие ядро (kernel) треугольной таблицы.
i-ым ядром треугольной таблицы называется ее прямоугольный фрагмент, верхней
гранью которого является i-ая строка, и простирающийся вниз от этой i-ой строки
до последней строки таблицы. На нижеследующем примере выделено 3-ье ядро треугольной
таблицы.
| 1 |
Precondition1 |
Action1 |
Action2 |
Action3 |
Action4 |
| 2 |
Precondition2 |
Add1 |
| 3 |
Precondition3 |
Add1/2 |
Add2 |
| 4 |
Precondition4 |
Add1/2,3 |
Add2/3 |
Add3 |
| 5 |
|
Add1/2,3,4 |
Add2/3,4 |
Add3/4 |
Add4 |
| |
0 |
1 |
2 |
3 |
4 |
Последовательность действий плана, начиная с i-ого действия,
применима в текущем состоянии, если все помеченные формулы в i-ом ядре истинны
в этом состоянии. Это легко показать на примере. Пусть на вышеприведенном рисунке
все помеченные формулы в 3-ем ядре истинны в текущем состоянии (иными словами,
ядро истинно). Очевидно, что действие Action3 применимо, т.к. все
помеченные формулы в строке 3 истинны. Когда действие Action3 применяется,
порождается новое состояние, в котором Add3 - множество формул, добавленных
Action3 - будет истинно. Теперь применимым стало действие Action4,
т.к. все помеченные формулы в строке 4 истинны: те, что были внутри ядра, были
истинны еще до применения Action3, а те, что вне ядра, истинны, т.к.
являются элементами списка добавления Action3. И так далее.
Первое ядро содержит множество достаточных условий для применения
плана в целом. Т.е. конъюнкция формул из нулевого столбца будет предусловием
всего плана.
Применение i-ого действия означает также переход от истинного
i-ого ядра к истинному (i+1)-му ядру.
Теперь поговорим об обобщении. Это довольно сложная процедура,
поэтому опишем ее подробно и постараемся рассматривать все на примерах. Начнем
с описания схем действий для этих примеров. Пусть робот (для управления которым
создавался STRIPS) умеет проходить через дверь из одной комнаты в другую и умеет
переносить предметы из одной комнаты в другую. Это можно описать следующими
схемами действий.
go_through (door, room1, room2)
precondition = InRoom(ROBOT, room1) & Connects(door, room1, room2)
delete list = { InRoom(ROBOT, room1) }
add list = { InRoom(ROBOT, room2) }.
push_through (box, door, room1, room2)
precondition = InRoom(ROBOT, room1) & InRoom(box, room1) &
Connects(door, room1, room2)
delete list = { InRoom(ROBOT, room1), InRoom(box, room1) }
add list = { InRoom(ROBOT, room2), InRoom(box, room2) }.
Существует также аксиома: ("
x, y, z) [ Connects(x, y, z) —> Connects(x, z, y) ].
Пусть мы решаем задачу "принести в комнату A ящик из комнаты
B, при этом робот изначально находится в комнате A". В качестве решения
этой задачи может быть найден план:
go_through(DOOR1, ROOMA, ROOMB),
push_through(BOX1, DOOR1, ROOMB, ROOMA).
Этому плану соответствует следующая треугольная таблица.
| 1 |
InRoom(ROBOT, ROOMA)
Connects(DOOR1, ROOMA, ROOMB) |
go_through(DOOR1, ROOMA, ROOMB) |
push_through(BOX1, DOOR1, ROOMB, ROOMA) |
| 2 |
InRoom(BOX1, ROOMB)
Connects(DOOR1, ROOMA, ROOMB)
Connects(x, y, z) —> Connects(x, z, y) |
InRoom(ROBOT, ROOMB) |
| 3 |
|
|
InRoom(ROBOT, ROOMA)
InRoom(BOX1, ROOMA) |
| |
0 |
1 |
2 |
Каким же образом выполнять обобщение такой таблицы, а следовательно,
и плана? Просто заменить каждую константу (ROOMA, ROOMB, DOOR1, BOX1) некоторым
параметром (например, rm1, rm2, dr1, bx1, соответственно) нельзя в виду следующих
причин:
- Некоторые константы должны иметь специфические значения, чтобы план оставался
корректным. Пусть, например, схема второго действия у нас такова, что всегда
выполняется только перенос объектов из комнаты B в комнату A через дверь DOOR1.
Получим следующий план:
go_through(DOOR1, ROOMA, ROOMB),
special_push(BOX1).
В этом плане нельзя обобщать константу ROOMB в первом действии, иначе схема
плана может стать некорректной. Ведь если робот уйдет в комнату, отличную
от ROOMB, действие special_push станет неприменимым. Корректным обобщение
здесь было бы следующее:
go_through(dr1, rm1, ROOMB),
special_push(bx1).
- Второй причиной является то, что, выполняя непосредственную замену констант
на параметры, мы утратим некоторую степень общности, которая могла бы быть
полезна. Выполняя простую замену, мы получим:
go_through(dr1, rm1, rm2),
push_through(bx1, dr1, rm2, rm1).
Но существует более общая абстракция этого плана, которая могла бы быть полезна:
go_through(dr1, rm1, rm2),
push_through(bx1, dr2, rm2, rm3).
Эта абстракция пригодна не только для того, чтобы отнести ящик в ту комнату,
из которой пришли. Она позволяет отнести ящик в любую смежную комнату, в которую
есть дверь.
Путь, ведущий к корректному выполнению обобщения, несколько более
сложен. Всю деятельность процедуры обобщения можно разделить на два этапа. Ниже
мы приводим подробное описание этой процедуры.
Первый шаг заключается в обобщении (lifting)
треугольной таблицы до наиболее общей формы. В нулевой колонке каждый экземпляр
параметра замещается уникальным параметром (множественное вхождение одной и
той же константы замещается разными параметрами). В оставшейся части таблицы
находятся все те же формулы из списков добавлений действий, но вместо действий
берутся схемы действий с уникальными именами параметров. Эти уникальные параметры
находят свое отражение и в списках добавлений, а, следовательно, и в треугольной
таблице. После выполнения первого шага, вышеприведенная таблица имела бы следующий
вид:
| 1 |
*InRoom(p1, p2)
*Connects(p3, p4, p5) |
go_through(p11, p12,
p13) |
push_through(p14,
p15, p16, p17) |
| 2 |
*InRoom(p6, p7)
*Connects(p8, p9, p10)
*Connects(x, y, z) —> Connects(x, z, y) |
*InRoom(ROBOT, p13) |
| 3 |
|
|
InRoom(ROBOT, p17)
InRoom(p14, p17) |
| |
0 |
1 |
2 |
(* - помеченные формулы - должны быть истинны для того,
чтобы план был выполним)
На втором шаге ограничиваем обобщенную таблицу так,
чтобы:
- помеченные формулы в каждой строке обеспечивали выполнимость
действия, соответствующего этой строке;
- обеспечиваем, чтобы изначальная таблица являлась частным случаем обобщенной
(с учетом ограничений).
Чтобы наложить ограничения, мы повторим процессы доказательства
истинности предусловий действий. Для этого мы используем помеченные формулы
в обобщенной таблице в качестве аксиом, а формулы предусловий действий в качестве
теорем, которые нужно доказать. Каждое новое доказательство строится по образу
и подобию оригинального доказательства предусловия (которое выполнялось в момент
построения плана). Т.е. применяется правило резолюции на тех же формулах и выполняется
унификация по тем же литералам, что и в оригинальном доказательстве. Такой процесс
доказательства гарантирует, что оригинальное доказательство будет частным случаем
нового обобщенного доказательства. А это обеспечит то, что оригинальная таблица
будет частным случаем обобщенной. Всякая подстановка параметра вместо константы
или другого параметра в новом доказательстве вносит ограничение на общность
плана, и отражается в обобщенной таблице. Действительно, когда мы выполняем
унификации, мы связываем отдельные параметры, указывая, что на самом деле, это
один параметр. Эта унификация отражается во всей таблице (а значит и в обобщенном
плане). Например, в процессе нового (уже с уникальными параметрами) доказательства
предусловия действия go_through, мы установим, что параметр p1 - это ROBOT,
а p2=p4=p12. Покажем это в деталях на примере процесса доказательства.
Из описания действия и таблицы следует, что отрицание доказываемого
предусловия (для метода резолюций) имеет следующий вид:
¬InRoom(ROBOT, p12) v ¬Connects(p11, p12, p13).
Выполняем унификацию с InRoom(p1, p2), получаем унификатор {p1=ROBOT, p2=p12},
применяем правило резолюции.
Получаем резольвенту ¬Connects(p11, p2, p13).
Выполняем унификацию с Connects(p3, p4, p5), получаем унификатор {p3=p11, p2=p4,
p5=p13}, применяем правило резолюции.
Доказательство завершено. Получили набор подстановок, которые и найдут свое
отражение в итоговой таблице.
В итоге, после выполнения второго шага, мы получим следующую
таблицу для вышеприведенного примера.
| 1 |
InRoom(ROBOT, p2)
Connects(p3, p2, p5) |
go_through(p3, p2,
p5) |
push_through(p6,
p8, p5, p9) |
| 2 |
InRoom(p6, p5)
Connects(p8, p9, p5)
Connects(x, y, z) —> Connects(x, z, y) |
InRoom(ROBOT, p5) |
| 3 |
|
|
InRoom(ROBOT, p9)
InRoom(p6, p9) |
| |
0 |
1 |
2 |
Фактически обобщение готово. Правда необходимо еще учесть один
важный фактор, который может приводить к несогласованности в обобщенной таким
образом таблице.
Рассмотрим следующий пример. Пусть у нас есть простой план: push(BOX1,
LOC1), push(BOX2, LOC2). Схема действия push описывается следующим образом:
push (box, location1, location2)
precondition = InRoom(box, location1)
delete list = { InRoom(box, location1) }
add list = { InRoom(box, location2) }.
Обобщение этого плана вышеуказанным методом даст следующую треугольную
таблицу.
| 1 |
At(bx1, loc1) |
push(bx1, loc1, loc2) |
push(bx2,
loc2, loc3) |
| 2 |
At(bx2, loc2) |
At(bx1, loc2) |
| 3 |
|
At(bx1, loc2) |
At(bx2, loc3) |
| |
0 |
1 |
2 |
Теперь, если планировщик в процессе решения очередной задачи
означит параметры следующим образом: bx1=bx2=BOX1, loc1=LOCA, loc2=LOCB, loc3=LOCC,
то мы получим, что после выполнения плана один и тот же предмет находится одновременно
в двух различных местах! Причина в том, что мы полагали, что удаляемые формулы
в обобщенной таблице будут те же самые, что и в необобщенной. В данном же примере,
формула At(bx1, loc2) должна быть удалена действием push(bx2, loc2, loc3), если
bx1=bx2, и не удалена в противном случае. Эту проблему можно решить внесением
в таблицу следующей поправки.
| 1 |
At(bx1, loc1) |
push(bx1, loc1, loc2) |
push(bx2,
loc2, loc3) |
| 2 |
At(bx2, loc2) |
At(bx1, loc2) |
| 3 |
|
¬(bx1=bx2) —> At(bx1, loc2) |
At(bx2, loc3) |
| |
0 |
1 |
2 |
Итак, чтобы поправить ситуацию, нужно учесть такие условные
удаления (conditional deletion). После того, как построена обобщенная таблица
и установлены ограничения, просматриваются списки удаления каждого действия,
начиная с первого. Список удаления i-ого действия применяется к формулам i-ой
строки для того, чтобы определить, какие формулы останутся в (i+1)-ой строке.
В ходе этого процесса могут выявиться условные удаления - случаи, когда возможна
унификация формулы из строки таблицы с формулой из списка удаления и при этом
требуется, чтобы некоторый параметр p1 заменялся другим параметром p2 или константой
C1. В этом случае формула будет унифицирована с формулой из списка удаления
только, когда p1 и p2 инстанциированы одной и той же константой или когда p1
инстанциирована константой C1. В таких случаях формулу в следующей строке замещают
импликацией вида:
¬(p1=p2) —> formula
или
¬(p1=C1) —> formula
Если формула, которая была замещена, являлась помеченной, то необходимо выполнить
еще одну модификацию таблицы. Если формула F обеспечивала выполнимость предусловия
j-ого действия и была замещена импликацией ¬(p1=p2) —> F, то формула
¬(p1=p2) должна быть добавлена как помеченная в ячейку [j, 0]. Это добавление
гарантирует, что предусловие j-ого действия может быть доказано.
В оригинальном алгоритме присутствует еще один шаг постобработки,
который влияет на эффективность, но мы не будем его здесь рассматривать.
Теперь мы получили корректный обобщенный план или макрооператор
или MACROP. Его можно использовать при построении новых планов наравне с основными
схемами действий.
Рассмотрим, как планировщик извлекает релевантную последовательность
действий из макрооператора. Напомним, что (i+1)-ая строка треугольной таблицы
(за исключением перовой ячейки) представляет собой список добавления Add1,...,i
первых i действий плана - Action1, ..., Actioni. Т.е.
таблица, содержащая план из n шагов, содержит также n списков добавления, которые
могут быть использованы для уменьшения различия, возникшего в процессе планирования.
Планировщик проверяет все списки добавления и выбирает тот, который лучше уменьшает
различие.
Предположим, планировщик выбрал i-ый список добавления (причем
i<n). Т.к. этот список добавления формируется первыми i действиями в таблице,
то остальные действия (после i) нас больше не будут интересовать. А вместе с
ними не представляют интереса и действия, которые не вносят вклад в интересующие
нас формулы (формулы, которые уменьшают различие между целевым и текущим состояниями).
Например, можно убрать те действия, назначением которых в плане было лишь обеспечение
выполнения действий после i. Т.е. даже из диапазона Action1, ...,
Actioni нам могут понадобиться не все действия.
Таким образом, треугольная таблица представляет собой целое семейство
схем действий! Как только планировщик выбирает подходящий список добавления,
мы должны будем извлечь из этого семейства схему некоего "макродействия",
которое предоставляет нужный список добавления.
Рассмотрим на примере, как производится извлечение схемы "макродействия".
Пусть у нас есть следующая треугольная таблица.
| 1 |
*1,*2 |
Action1 |
Action2 |
Action3 |
Action4 |
Action5 |
| 2 |
*3 |
6,*7,8 |
| 3 |
*4 |
*6,8 |
9,10 |
| 4 |
*5 |
6,8 |
10 |
11 |
| 5 |
*2 |
6 |
*10 |
11!!! |
12,13 |
| 6 |
|
6 |
10 |
|
12 |
14 |
| |
0 |
1 |
2 |
3 |
4 |
5 |
Здесь как и ранее * обозначает помеченные формулы (предусловия),
а !!! обозначает нужный нам эффект (уменьшающий различие между целевым и текущим
состояниями). Т.к. формула 11 (которая нам требуется) находится в списке предусловий
действия 5, то пятое действие нам не нужно. При этом мы снимаем пометки с требуемых
пятому действию формул (т.е. 2 и 10 в строке 5). Теперь идем по таблице справа
налево и ищем столбцы в которых нет помеченных формул (ни *, ни !!!). Первым
таким столбцом будет четвертый. Т.е. действие 4 нам тоже не нужно. Снимаем пометки
с формул в строке 4 (пятая формула больше не требуется). Продолжаем обход таблицы
справа налево. Следующим удаляемым действием станет действие 2 (с десятой формулы
мы сняли пометку, когда удаляли действие 5). Опять снимаем пометки (уже в строке
2) - формулы 3 и 7 больше не нужны. В итоге получим таблицу следующего вида.
| 1 |
*1,*2 |
Action1 |
Action3 |
| 2 |
*4 |
*6, 7, 8 |
| 3 |
|
6, 7, 8 |
11 |
| |
0 |
1 |
2 |
То есть для достижения эффекта, выраженного формулой 11, нам
понадобится только два действия из изначального макрооператора.
Как только схема "макродействия" извлечена, она может
быть использована точно так же, как и любая другая схема действия. В схеме выполняется
поиск ядра, которое выполнимо в текущей ситуации. В примере выше это либо набор
формул (1,2,4), либо (4,6). Если один из этих наборов формул выполняется, то
выбирается соответствующий набор действий (от номера ядра до последнего действия
таблицы). Если нет выполнимого ядра, то первое ядро выбирается в качестве новой
цели (хотя можно брать и любое другое ядро).
На этом история STRIPS заканчивается.
1973г. — HACKER
Годом позднее Джеральд Сусман разработал еще одну интересную
систему для решения задач [Sussman G.J., 1973],
основанную на методе анализа средств и целей и обладающую механизмом обучения.
Эта система получила название HACKER. В качестве механизма обучения Сусман использовал
упрощенный вариант обучения по прецедентам. Прецеденты сохранялись в библиотеке
прецедентов, названной Сусманом библиотекой ответов (answer library).
Когда система HACKER решала очередную задачу, она сначала проверяла, нет ли
в библиотеке ответов решения, чей образец применимости (pattern of applicability)
соответствует условиям задачи. Если такое решение находилось, то оно применялось.
Если нет, то HACKER находил новое решение. При построении нового решения система
могла использовать библиотеку ответов для разрешения частных подпроблем, а также
старалась избегать ошибок, с которыми она сталкивалась ранее. Новое решение
сохранялось в библиотеке ответов, проиндексированное по образцу применимости,
выведенному из постановки задачи. Таким образом, оно могло быть использовано
для решения подобных задач в будущем. Если решение в момент применения приводило
к ошибке, то использовались общие механизмы отладки для классификации и установления
природы ошибки. После этого решение редактировалось и перезаписывалось в библиотеке
ответов. Часто ошибка сама подвергалась обобщению и запоминанию, для того, чтобы
избегать ее уже при построении решения.
HACKER - это попытка совместить в одной системе процедурное и
декларативное представления знаний о предметной области, чтобы получить одновременно
легко расширяемый (декларативное представление) и эффективный (процедурное представление)
решатель задач. Ряд проблем система "знает" как решать (эти знания
могут приобретаться, например, посредством обучения). Метод решения - это процедурное
представление знаний. Процедура описывает порядок шагов и способ избежания негативного
взаимовлияния шагов. Процедурное представление обеспечивает высокую скорость
поиска известных решений. Декларативное представление знаний служит
залогом хорошей расширяемости описания предметной области. В этой форме могут
быть легко добавлены новые факты о мире (объекты, отношения).
Каждую новую задачу HACKER обрабатывает по следующей схеме. Сначала
проверяется, нет ли готового решения общего вида для данной проблемы. Т.е. выясняется,
не является ли новая задача частным случаем более общей задачи, метод решения
которой уже известен. Фактически, это проверка, нет ли в библиотеке ответов
процедуры, чей образец применимости (прототип) соответствует новой задаче. Если
такая процедура есть, то она и является планом. HACKER исполняет планы, т.е.
эта процедура интерпретируется. Если процедура исполняется успешно, то управление
возвращается пользователю, и он оценивает результаты работы. Если же готовое
решение отсутствует в библиотеке ответов или найденная процедура не срабатывает,
то HACKER "программирует" новое решение или отлаживает старое соответственно.
В первом случае HACKER пользуясь знаниями о предметной области и "общих
методах программирования" (programming technique) порождает новую процедуру
решения задачи. Т.е. фактически решение порождается на основе набора эвристик,
названных методами программирования, но в основе этих эвристик лежит анализ
средств и целей. Новое решение проверяется на предмет наличия известных видов
ошибок и при необходимости корректируется. В конечном счете, оно помещается
в библиотеку ответов. Во втором случае (ошибка при исполнении) включается механизм
отладки. Определяется вид ошибки и производится попытка корректировки процедуры.
Сусман особо выделяет ситуацию, когда некоторое действие плана
разрушает результат, достигнутый одним из предшествующих шагов. В системе HACKER
предложен механизм, позволяющий контролировать появление таких ситуаций, - механизм
защиты (protection mechanism). Он служит основой для выявления некорректных
планов такого рода и причин их некорректности. В дальнейшем эти знания могут
быть использованы при построении новых планов.
Механизм защиты опирается на следующую идею. У каждого шага в
плане есть, по крайней мере, одно назначение (purpose). Этим назначением
может быть либо вклад в общую цель, либо достижение предусловий последующих
шагов плана. Назначение может рассматриваться как некоторое утверждение, являющееся
либо частью общей цели, либо требующееся для исполнения последующих шагов плана.
Если на интервале от некоторого действия до точки реализации его назначения
происходит отрицание этого назначения (как утверждения), то такая последовательность
действий считается некорректной. Защитный механизм позволяет обнаруживать такие
некорректные случаи. Он контролирует неизменность назначения на соответствующем
интервале. Если значение истинности назначения (как утверждения) измениться,
то фиксируется ошибка, которая потом анализируется и делаются необходимые поправки.
В системе HACKER механизм защиты работает в процессе исполнения
плана, хотя эту идею можно легко перенести и на процесс генерации плана.
Однако такой защитный механизм не избавляет нас от всех проблем.
Простой пример, обнаруженный Аленом Брауном (Allen Brown), демонстрирует несостоятельность
такого подхода. Этот пример в дальнейшем стал называться аномалией Сусмана
(Sussman anomaly).
|
Начальное состояние
 |
Целевое состояние
|
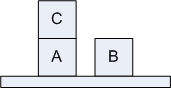
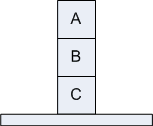
Задача заключается в построении пирамидки из
трех кубиков: A, B и C. Цель можно, например, выразить следующей конъюнктивной
формулой:
On (A, B) & On (B, C).
Начальное состояние выражается набором утверждений:
On (C, A), OnTable(A), OnTable(B), Clear(C), Clear(B).
Можно перемещать только те кубики, на которых сверху не стоит других
кубиков (Clear). |
| Рис. "Аномалия Сусмана" |
Очевидно, что задача решается посредством установки сначала кубика
B на кубик C, а затем кубик A ставится на кубик B, т.к. башенки строятся снизу
вверх. Но если мы сначала поставим кубик B на C, то для выполнения следующего
действия (установки A на B) должно быть истинным Clear(A). Для обеспечения этого
условия необходимо снять кубик C с A. А до этого потребуется снять B с C. Но
это приведет к некорректности с точки зрения защитного механизма, т.к. On(B,C)
- глобальная цель и не должна нарушаться на интервале от точки ее достижения
до конца выполнения плана.
Сусман пишет, что такие ситуации можно обрабатывать следующим
образом. Сначала разрешить нарушение ограничения механизма защиты с требованием
в дальнейшем вновь восстановить защищаемое условие.
В качестве итога отметим, что HACKER - это решатель задач, основанный
на анализе средств и целей, наборе эвристик и запоминании ранее найденных решений.
К тому, что сейчас принято называть системой планирования, HACKER можно отнести
с большой натяжкой. Тем не менее, эта система являлась важным шагом в развитии
теории интеллектуального планирования, т.к. вскрыла проблему зависимости подцелей
в составной цели (например, в цели, выраженной конъюнкцией литералов). Системы
STRIPS и HACKER разрабатывались исходя из предположения, что подцели всегда
можно достигать последовательно. Сначала можно достичь одну подцель, потом уже
из нового состояния достичь другую и т.д. Обе системы учитывали, что порядок
достижения подцелей может быть каким угодно. Но они не учитывали того, что может
потребоваться чередование (interleaving) шагов, служащих для достижения разных
подцелей. Утверждение о том, что подцели можно достигать последовательно, называется
допущением линейности (linearity assumption) и верно только в случае
независимости подцелей. Аномалия Сусмана - яркий пример ложности этого утверждения
в случае зависимых подцелей. Планировщики, учитывающие возможность чередования
шагов, служащих для достижения разных подцелей, называются нелинейными
(non-linear planners).
1974г. — InterPlan
После обнаружения аномалии Сусмана появился целый ряд работ,
посвященных решению этой проблемы. В частности Остин Тейт предложил подход
[Tate A., 1974] [Tate A., 1975],
основанный на переупорядочивании подцелей в процессе планирования. Реализация
этого подхода воплотилась в планировщике Interplan.
В своей работе Тейт рассматривает в качестве цели конъюнкцию
высказываний, выраженных атомарными формулами (будем называть эти высказывания
целями-конъюнктами). Цели-конъюнкты достигаются в определенной последовательности
и, будучи достигнутыми, уже не должны разрушаться до конца процесса планирования.
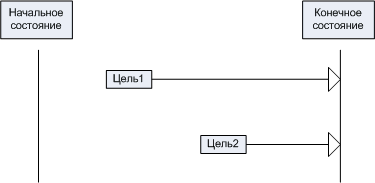
Тейт вводит понятие "период сохранности" цели-конъюнкта (holding period),
которым обозначает интервал времени от момента достижения цели-конъюнкта (когда
она стала окончательно истинной) до момента достижения целевого состояния. Периоды
сохранности и порядок достижения целей можно изобразить в виде следующей диаграммы.
Здесь время представлено в горизонтальном измерении. "Цель1"
и "Цель2" моменты достижения целей-конъюнктов. Стрелки изображают
период сохранности.
STRIPS достигает цели-конъюнкты в том порядке, в котором они
заданы. Если STRIPS не находит решения для такого порядка целей-конъюнктов,
он может изменить этот порядок.
Выбрав порядок достижения целей, STRIPS подбирает релевантные
действия для еще не достигнутых целей. Предусловия этих действий (снова конъюнкции)
будут выступать в качестве новых целей (назовем их подцели). Эти подцели должны
достигаться в моменты, непосредственно предшествующие достижению изначальной
цели-конъюнкта.
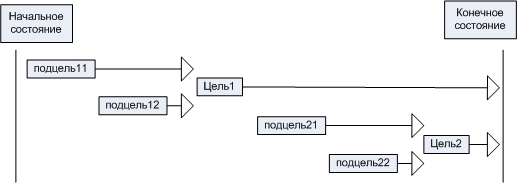
На уровне подцелей также возможны перестановки. Например, можно
поменять порядок достижения "подцели21" и "подцели22". Но
перестановки в STRIPS ограничены только перестановками на одном уровне. Т.е.
для вышеприведенного рисунка STRIPS допускает только 3 перестановки: "цель1"
с "цель2", "подцель11" с "подцель12" и "подцель21"
с "подцель22". Но для решения проблемы Сусмана требуется более сложная
перестановка.
Кроме того, и STRIPS и HACKER часто порождают более длинные планы,
чем необходимо. Это обусловлено тем, что они допускают разрушение достигнутого
эффекта и затем повторное его достижение.
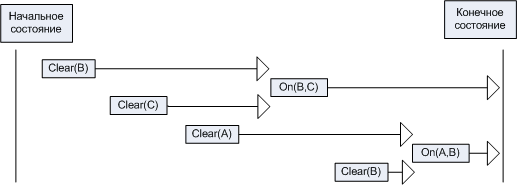
Однако, если допустить любые варианты чередования целей-конъюнктов
и подцелей, эта проблема может быть решена. Для решения проблемы Сусмана (On
(A, B) & On (B, C)) нам, например, потребуется такое чередование (для простоты
отображена только часть предусловий).
Т.е. подцель Clear(A) должна быть достигнута раньше цели-конъюнкта
On(B,C).
Планировщик Interplan (interleaving planning) учитывает необходимость
(в ряде случаев) перемещения подцелей по временной оси. Тейт пишет, что на самом
деле нужно рассмотреть лишь небольшое число возможных чередований. Следует пользоваться
допущением линейности (как в STRIPS), т.к. это очень мощная эвристика, но в
случае обнаружения противоречий следует учитывать возможность чередования. Если
противоречие обнаружено, то можно либо переставить цели более высокого уровня,
либо попробовать достичь их в противоположном порядке (например, поместить вторую
цель непосредственно перед первой).
Резюмируем. Interplan - планировщик на основе анализа средств
и целей с дополнительной эвристической функциональностью, позволяющей более
гибко упорядочивать цели-конъюнкты и подцели, чем это делал STRIPS. Этот планировщик
также не обладает полнотой и опирается на допущение о линейности. Однако более
развитые эвристические средства по манипулированию порядком целей позволили
ему справиться с аномалией Сусмана.
1974г. — ABSTRIPS
Неспособность STRIPS справляться с аномалией сусмана - не единственная
проблема этого планировщика. Сталкиваясь со сложными и большими описаниями предметных
областей, STRIPS-эвристики не спасают от комбинаторного взрыва. Нужно было искать
другие пути сокращения пространства поиска. Эрл Сасердоти предложил использовать
иерархию абстрактных пространств поиска для того, чтобы на каждом уровне абстракции
отделять действительно важную информацию от несущественных в данный момент деталей,
и тем самым отсекать нерелевантные ветви поиска уже на верхних уровнях абстракции
[Sacerdoti E.D., 1974]. Его идеи легли в основу
планировщика ABSTRIPS (Abstraction-Based STRIPS) - STRIPS-подобного планировщика
с поддержкой идеи абстрактных пространств поиска.
Хорошая эвристическая функция может отсекать большинство возможных
путей в пространстве поиска. Однако, если принимать во внимание все "детали"
пространства поиска, то оценочная функция (определяющая, куда идти дальше) будет
применена к большому количеству узлов, обусловленных этими "деталями".
Предложенный Сасердоти подход выполняет поиск сначала в абстрактном пространстве
(abstraction space) - упрощенном представлении пространства поиска, в котором
опущены несущественные детали. Когда решение в абстрактном пространстве поиска
найдено, все, что остается сделать, это учесть детали связей между шагами в
полученном решении. Это можно рассматривать как последовательность подзадач
в рамках изначальной задачи. Если эти подзадачи могут быть решены, то решение
всей проблемы тоже будет найдено. Если нет, то нужно продолжить планирование
в абстрактном пространстве для поиска альтернативного абстрактного решения.
Эта идея легко может быть расширена до иерархии абстрактных пространств поиска.
Каждый уровень дает все большую детализацию. Детали рассматриваются, только
когда найден план в вышележащем уровне иерархии. Таким образом, эвристика на
каждом уровне иерархии будет рассматривать значительно сокращенное пространство
поиска.
Абстрактное пространство поиска должно соответствовать двум критериям.
С одной стороны, оно должно в достаточной степени отличаться от детального пространства
для значительного повышения производительности. С другой стороны, оно не должно
быть настолько абстрактным, чтобы затруднить отображение абстрактного пространства
в конкретное (детальное). Для STRIPS-системы эти критерии удовлетворяются, только
если пользоваться уровнями детализации предусловий действий. Модель
мира (состояния) может оставаться неизменной; нет необходимости удалять несущественные
детали, т.к. они все равно будут проигнорированы действиями (нет предусловий
с их использованием). Нет смысла и в удалении действий. Те из них, которые работают
с деталями, не будут признаны как релевантные. Изменение списков удаления и
добавления приведет к существенному усложнению отображения планов между уровнями
иерархии пространств поиска.
Таким образом, иерархии пространств различаются только уровнем
детализации предусловий действий. Предусловие в абстрактном пространстве содержит
меньше литералов, чем в детальном. Опускаются такие литералы, для которых можно
легко найти план их достижения.
Технически, уровни детализации реализуются путем присвоения каждому
литералу в предусловиях значения критичности ("criticality" value).
В наивысшем уровне иерархии присутствуют только литералы с наибольшим значением
критичности. В более низких уровнях включаются также менее критичные литералы.
Присвоение значений критичности можно выполнять различными способами.
Можно, например, вручную назначить уровни критичности всем литералам во всех
предусловиях действий, опираясь на знания о предметной области. В ABSTRIPS уровни
критичности назначаются полуавтоматически. Сначала на множестве всех предикатов
вручную задается частичный порядок (ранги). Чем выше ранг предиката, тем более важными считаются предусловия, формирующиеся на базе этого предиката. Данный частичный порядок используется
для задания порядка проверки литералов в предусловиях действий. Это осуществляется следующим образом. Сначала всем
литералам, на истинность которых нельзя повлиять имеющимися действиями, присваивается
максимальное значение критичности. Затем оставшиеся литералы проверяются в порядке убывания
рангов их предикатов. Если короткий план может быть найден для достижения литерала
из состояния, в котором все ранее рассмотренные литералы истинны, то литералу
назначается уровень критичности, равный рангу его предиката. Если короткий план найти
не удается, то литералу присваивается значение критичности, превосходящее максимальный ранг (но не превышающее упомянутое ранее максимальное значение критичности!).
Планирование осуществляет рекурсивная процедура. Она принимает
два параметра: текущее значение критичности (показывающее уровень абстракции)
и "абстрактный план" (skeleton plan), содержащий еще недостигнутые
цели (цели, соответствующие текущему значению критичности). Для постановки задачи
перед планировщиком используется специальное действие-заглушка, предусловием
которого является целевая формула (а эффекта нет). Всем литералам в предусловии
действия заглушки выставляется максимальное значение критичности. Текущим значением
критичности (параметр процедуры) также выставляется максимальное значение.
На наивысшем уровне абстракции ищется план достижения предусловий
действия-заглушки (т.е. главной цели). При этом у действий в предусловиях учитываются
только литералы, соответствующие текущему значению критичности. Когда план найден,
программа уменьшает значение критичности и из полученного плана строит новый
"абстрактный план", добавляя литералы, соответствующие новому значению
критичности. После чего выполняется рекурсивный вызов. Новый вызов добавляет
в план действия для достижения новых предусловий (соответствующих новому значению
критичности). При этом контролируется, чтобы план оставался выполнимым. Последним
шагом в "абстрактном плане" всегда является действие-заглушка. Это
гарантирует, что проверка выполнимости учтет также сохранение достигнутой ранее
исходной цели. Рекурсия продолжается, пока не будет найдено решение проблемы
на самом низком уровне абстракции (минимальное значение критичности). Если на
каком-то этапе план найти не удается, то выполняется откат и поиск продолжается
на вышележащем уровне абстракции.
Кроме этого, в ABSTRIPS реализована отложенная инстанциация параметров
действий и эвристика выбора следующего узла в дереве поиска, учитывающая не
только расстояние до цели, но и расстояние от начального состояния (во избежание
построения излишне длинных планов). Не будем рассматривать это подробно.
1974г. — WARPLAN
Еще одно решение проблемы с чередованием шагов в нелинейных планах
было предложено Дэвидом Уорреном [Warren D., 1974].
Его подход заключался в отказе от STRIPS-овского варианта анализа средств и
целей. Вместо него был предложен несколько иной подход, названный регрессией
(regression). В STRIPS поиск подходящих действий велся от цели, но построение
плана выполнялось от начального состояния. Регрессия осуществляет построение
плана с конца (от цели к начальному состоянию). При этом рассматриваются все
возможные способы достижения каждой из подцелей и все возможные порядки их достижения.
Достигнутые цели не должны были разрушаться в текущей ветви поиска. Именно,
рассмотрение всех возможных порядков позволяет преодолеть проблему с чередованием.
Планировщик warplan, реализующий этот подход, был написан Уорреном
на прологе и состоял всего лишь из ста строк кода.
РАЗЫСКИВАЕТСЯ ПЕРВОИСТОЧНИК для составления более подробного
обзора !!!
1975г. — NOAH (Nets Of Action Hierarchies)
NOAH - первый планировщик, допускающий частичное упорядочение
(partial order) действий в плане. При таком подходе, план - это набор отношений
порядка между действиями. Связный план можно получить из набора частично упорядоченных
действий путем линеаризации (linearization). Кроме этого, такой подход
делает возможным наличие параллельных ветвей в плане.
NOAH - первый иерархический планировщик. Иерархическое планирование
предполагает, что процесс составления плана - это процесс постепенной детализации
решения. Действия в NOAH могут быть простыми и составными (раскладываться на
набор действий-составляющих). Составные действия содержат в себе знания о типовых
решениях часто встречающихся задач.
Планировщик использовался в "Системе компьютерной консультации"
(Computer Based Consultant Project).
Для составления обзора РАЗЫСКИВАЕТСЯ ПЕРВОИСТОЧНИК !!!
[Sacerdoti E.D., 1975]
[Sacerdoti E.D., 1977]
1976г. — NONLIN
Очередной важной вехой в истории планирования стал планировщик
NONLIN (Non-linear planner). Идеологически этот планировщик является развитием
планировщика NOAH. Однако Тейт вводит новый термин - задача (task)
- положивший начало новому направлению, называемому HTN-планированием (HTN -
hierarchical task network - иерархическая сеть задач). По своей сути (идее,
механизмам) HTN-планирование и иерархическое планирование являются одним и тем
же. Однако с точки зрения терминологии, HTN - это такое иерархическое планирование,
в котором используется понятие задачи.
Планировщик NONLIN появился как часть проекта "The Planning:
a joint AI/OR approach" [Tate A., 1976] [Tate
A., 1977]. Целью этого проекта было создание программы, помогающей пользователям
составлять сетевые графики проектов (project network). Из названия ясно, что
проект опирался на два различных подхода: искусственный интеллект (AI) и исследование
операций (OR - operational research). При этом AI отводилась роль построения
сетевого графика, а на долю OR выпадал анализ критического пути и оптимизация
графика. Мы коснемся только вопросов построения графика. Но сначала более детально
рассмотрим понятие "задача".
Задача является одним из ключевых терминов, которым оперируют
составители сетевых графиков. Обычно, проект рассматривается как частично упорядоченный
набор задач (task), которые необходимо решить. Например, проект построения здания
может состоять из следующей последовательности задач:
- Заложить фундамент.
- Возвести стены.
- Соорудить крышу.
- Провести коммуникации.
- Выполнить внутреннюю отделку помещений.
Некоторые задачи могут разрешаться только в определенном порядке,
а некоторые можно решать параллельно.
Для многих задач известны типичные методы их решения.
Как правило, методы специфичны для различных задач и предметных областей. Например,
задачу "заложить фундамент" можно решить при помощи следующего метода:
сначала "вырыть котлован", затем "забить сваи", и наконец,
"построить цоколь". Метод - это декомпозиция задачи на набор частично
упорядоченных подзадач (которые, в свою очередь, так же могут быть разбиты на
еще более мелкие подзадачи). Таким образом, мы приходим к понятию иерархии
задач. Проект в целом может рассматриваться как один из возможных методов
решения задачи более высокого уровня. Т.е. пример выше можно рассматривать как
метод решения задачи "построить здание".
Итак, задачи могут состоять из подзадач. Те, в свою очередь,
могут дробиться на еще более мелкие подзадачи. В конечном счете, все сводится
к задачам, дальнейшее дробление которых не представляет интереса с точки зрения
решаемой глобальной проблемы. Такие задачи называются примитивными.
Одна и та же задача может быть решена различными методами. Иногда
целесообразность применения того или иного метода задачи зависит от каких-то
определенных факторов (ситуации, сложившейся в предметной области).
Как уже отмечалось, методы решения задач специфичны в разных
предметных областях. Т.е. метод несет в себе некоторое дополнительное знание
об этой предметной области. Носителями специфичных знаний являются эксперты.
Таким образом, методы решения задач формулируются экспертами. Например, методы
для решения задачи "проводка коммуникаций" формулируются экспертом
по проводке коммуникаций.
Определившись с терминологией, вновь обратимся к проблеме составления
сетевого графика, как проблеме планирования. NONLIN - иерархический планировщик.
Т.е. поиск решения представляется собой постепенное уточнение решения.
В контексте проблемы построения сетевых графиков искомым планом
является сам проект, график которого необходимо получить. Как упоминалось ранее,
проект - это частично упорядоченный набор задач. Целью NONLIN является получение
проекта, состоящего только из примитивов.
Для описания задач в иерархической форме был разработан специальный
формализм, названный формализмом задач (task formalism - TF). Основным
синтаксическим элементом этого формализма является метод решения задачи.
В TF метод описывается при помощи конструкции OPSCHEMA или ACTSCHEMS (в формальном
смысле это синонимы). OPSCHEMA определяет:
- для решения какой задачи предназначен данный метод,
- из каких подзадач состоит решение,
- в каком порядке нужно решать подзадачи,
- при каких условиях метод применим,
- какие условия должны быть соблюдены при переходе к решению очередной подзадачи,
- какие изменения модели мира произведет применение схемы (эффекты).
Формально OPSCHEMA определяется следующим образом (здесь представлено
упрощенное определение).
| OPSCHEMA |
::= |
OPSCHEMA имя_метода |
| |
|
PATTERN <решаемая_задача> |
| |
|
[<детализация>] |
| |
|
[EFFECTS <эффект>+] |
| |
|
[VARS <определение_переменной>+] |
| |
|
END; |
Задача, способ решения которой описывается методом, задается
полем PATTERN. По сути, <решаемая_задача> это атомарная формула, которая
истинна, когда задача решена. Однако формальное представление ее в NONLIN несколько
нетрадиционно, и мы не будем вдаваться в детали.
Если решаемая задача является примитивом, то метод ее решения
не уточняется и поле <детализация> отсутствует. Если задача не примитив,
то присутствует поле <детализация>, формальное описание которого будет
приведено ниже.
Поле EFFECTS определяет изменение модели мира, вызванное применением
данного метода. Обычно эффекты указываются только для примитивов, в эффекты
сложных задач складываются из эффектов составляющих. <Решаемая_задача>,
указанная в поле PATTERN также становится истинной, после применения метода.
Поле VARS определяет переменные, используемые в описании метода.
Решаемая задача обычно формулируется как параметрическая (т.к. определяется
через предикат), тогда в поле VARS перечисляются имена всех параметров.
Теперь определим формально детализацию (т.е., собственно, метод).
| детализация |
::= |
EXPANSION |
| |
|
<узел_детализации>* |
| |
|
[ORDERINGS <отношение_порядка>+] |
| |
|
[CONDITIONS <определение_предусловия>+] |
Каждый узел детализации имеет порядковый номер и может быть сформулирован
двумя способами.
- Как подцель - GOAL <решаемая_подзадача>. В этом случае выполняется
проверка: "решена ли уже эта подзадача". Если это так, то дальнейшего
ее уточнения не происходит. Если же подзадача еще не решена, то выполняется
поиск метода для ее решения.
- Как подзадача - ACTION <решаемая_подзадача>. В этом случае
обязательно выполняется поиск метода решения подзадачи.
Поле ORDERINGS определяет порядок выполнения подзадач. Отношения
порядка определяются в виде пар: "<предшествующая_подзадача> --->
<последующая_подзадача>".
Поле CONDITIONS определяет:
- условия, при которых можно приступать к решению определенных
подзадач (предусловия подзадач),
- условия применимости метода в целом (предусловия метода).
Предусловия подзадач зависят либо от внешних факторов по отношению к методу
(UNSUPERVISED), либо от внутренних (SUPERVISED). Предусловие схемы - это условие,
определяющее релевантность такого способа решения задачи в данных условиях.
Этот вид условий обозначается ключевым словом HOLDS или, в более новой версии
системы, USEWHEN.
В качестве примера использования такого формализма приведем описание
метода строительства здания.
OPSCHEMA Строительство_здания
PATTERN <<Построить_новое_здание>>
EXPANSION
1 ACTION <<Заложить_фундамент>>
2 ACTION <<Возвести_стены>>
3 ACTION <<Соорудить_крышу>>
ORDERINGS 1--->2 2--->3
END;
Это описание говорит о том, что метод пригоден для решения задачи
"Построить новое здание". При этом, задача раскладывается на 3 составляющие,
которые решаются последовательно. Детализация одной из этих подзадач - Построение
фундамента - может быть описана, например, так.
OPSCHEMA Строительство_фундамента
PATTERN <<Заложить_фундамент>>
EXPANSION
1 GOAL <<Вырыть_котлован>>
2 ACTION <<Вбить_сваи>>
3 ACTION <<Построить_цоколь>>
ORDERINGS 1--->2 2--->3
CONDITIONS
USEWHEN <<Почва_твердая>> AT SELF
END;
Здесь "рытье котлована" помечено как подцель. Т.е.
если котлован уже есть, то его рыть не нужно, а если нет, то "вырыть котлован"
становится подзадачей и решается постепенным уточнением до примитивов.
Проблема перед планировщиком ставится по аналогии с детализацией
конструкции OPSCHEMA. Отличие заключается в том, что вместо слова EXPANSION
используется слово PLAN. Например, план строительства нового здания может быть
задан так:
PLAN GOAL <<Построить_новое_здание>>
Естественно, можно задавать несколько целей.
Работа алгоритма заключается в детализации еще не детализированных
узлов до примитивов. При этом контролируется выполнимость всех условий, заданных
в методах решения.
NONLIN обходит пространство поиска полностью (в отличие от NOAH).
Если в какой-то момент времени была выбрана неверная детализация (метод решения),
то будет выполнен откат и выбор альтернативных вариантов.
В NONLIN используются идеи Interplan для разрешения проблемы
чередования.
1983г. — SIPE
Этот планировщик известен тем, что осуществляет планирование
ресурсов, т.е. работает не только с логическими выражениями, но и с численными
величинами. Относится к числу HTN-планировщиков. Разработан Дэвидом Уилкинсом
(David Wilkins).
Для составления подробного обзора разыскивается первоисточник!!!
[Wilkins D.E., 1983]
[Wilkins D.E., 1984]
1987г. — TWEAK
TWEAK - еще один планировщик, использующий частичное упорядочивание
действий в плане. Однако, в отличие от NOAH и NONLIN он не является иерархическим.
Автор этого планировщика - Дэвид Чепмен (David Chapman) - подверг критике большинство
ранее разработанных планировщиков за их недостаточно строгое определение методов
решения задачи планирования, эвристичность и сложность (особенно это касалось
нелинейных планировщиков). Чепмен приводит [Chapman
D., 1987] строгое математическое определение задачи планирования и метода,
который он использовал для ее решения. Кроме того, в его работе представлена
терминология, которая в дальнейшем получила широкое распространение в планировании.
Чепмен рассматривал планирование не как процесс последовательной
генерации шагов, а как процесс наложения ограничений, которым должен соответствовать
результирующий план. TWEAK он называет планировщиком, накладывающим ограничения
(constraint-posting planner). Наложение ограничений (constraint posting)
- это способ (процесс) определения объекта, в данном случае плана, путем постепенного
перечисления частичных описаний (ограничений), которым он (объект) должен
соответствовать. С другой стороны, наложение ограничений можно рассматривать
как стратегию поиска, при которой вместо генерирования и проверки отдельных
ветвей поиска, целые куски пространства поиска постепенно удаляются из рассмотрения
(посредством ограничений) до тех пор, пока не останутся только альтернативы,
удовлетворяющие условиям поиска.
Такой подход можно рассматривать как постепенное уточнение незавершенного
плана (incomplete plan). Изначально незавершенный план состоит из описания
начального состояния и не содержит действий и ограничений. В процессе планирования
план уточняется путем добавления схем действий и ограничений (на порядок следования
схем действий и значения их параметров). Незавершенный план может быть завершен
(be completed) несколькими разными способами (в зависимости от того, какие схемы
действий будут добавлены и какие ограничения будут наложены в дальнейшем), т.е.
он соответствует классу завершенных планов.
Архитектурно TWEAK можно разделить на две составляющие: управляющую
процедуру (top-level control structure) и процедуру достижения цели (goal-achievement
procedure). Первая из них в цикле осуществляет выбор очередной подцели. Изначальная
цель может состоять из нескольких подцелей. Кроме этого, добавление в план новых
действий может приводить к появлению новых подцелей, обусловленных предусловиями
этих действий. Перебор целей осуществляется в ширину, т.е. сначала рассматриваются
способы достижения исходных подцелей, потом подцелей, появившихся в результате
добавления действий для достижения исходных подцелей и т.д. Если очередная цель
оказывается недостижимой, то выполняется откат и ищется альтернативное решение.
Таким образом, осуществляется исчерпывающий поиск, т.е. если план существует,
то он будет найден.
Вторая процедура - процедура достижения цели - обеспечивает достижимость
одной определенной цели, если это возможно. Эта процедура опирается на критерий
модальной истинности (modal truth criterion), определяющий условия, когда
некоторое высказывание гарантированно будет иметь значение "истина".
Процедура достижения цели обеспечивает выполнимость этого условия для достигаемой
цели. Чтобы сформулировать критерий модальной истинности, нужно сначала определить
ряд вспомогательных понятий.
Начнем со способа представления плана в TWEAK. Завершенный
план (complete plan) - это полное упорядочение (total order) конечного
множества шагов, т.е. линейная цепочка шагов. Шаг (step) служит для
обозначения действия в плане. Порядок (order) символизирует временную
шкалу. План исполняется посредством выполнения соответствующих шагам действий
в заданном порядке.
Любой шаг имеет конечное множество предусловий (preconditions)
- фактов, которые должны быть истинны в модели мира непосредственно перед исполнением
соответствующего шагу действия. У шага также есть конечное множество постусловий
(postconditions) - фактов, которые гарантировано будут истинны в модели мира
после исполнения действия, соответствующего шагу.
Пре- и постусловия выражаются при помощи высказываний
(proposition). Высказывание имеет контент (content) - некоторый кортеж
элементов (element). Высказывание может быть отрицательным (negated).
Элементами могут быть переменные или константы. Функции, логические операции
и кванторы недопустимы в качестве элементов. Примером высказывания может служить
следующая конструкция: ~(on a x). Здесь контент состоит из трех элементов: on,
a и x. Знак "~" используется для обозначения отрицания. Два высказывания
являются отрицаниями друг друга, если одно отрицательное, а другое положительное,
и у них одинаковый контент.
План в TWEAK может быть незавершенным по двум причинам. Во-первых,
временной порядок может быть неполностью определен, при помощи временных ограничений
(temporal constraints). Временное ограничение - это требование того,
чтобы один шаг предшествовал другому. Таким образом, временные ограничения всего
лишь задают частичный порядок на множестве шагов. Во-вторых, шаги могут быть
неполностью определены посредством ограничений соозначивания (codesignation
constraints). Соозначивание - это своеобразное отношение эквивалентности
на множестве переменных и констант. В завершенном плане каждая переменная, фигурирующая
в пред- или постусловии, должна быть соозначена с какой-нибудь константой -
связана (be bound to). Во время исполнения эти константы будут подставлены в
действия вместо переменных. Две константы не могут быть соозначены друг с другом.
Ограничение соозначивания определяет как соозначивание (codesignation), так
и несоозначивание (noncodesignation) элементов. Два высказывания соозначены,
если оба являются отрицательными или оба являются положительными и их контенты
имеют одинаковую длину и соответствующие элементы контента соозначены. Например,
(on A x) и (on A y) соозначены, если x и y соозначены (здесь A - константа).
Будем говорить "необходимо p" (necessarily p), если
p истинно во всех завершениях незавершенного плана. Аналогично, будем говорить
"допустимо p" (possibly p), если p истинно в некоторых завершениях.
Два высказывания в незавершенном плане необходимо-соозначны,
если они соозначены во всех завершениях. Можно сделать два возможно-соозначенных
высказывания необходимо-соозначенными, наложив ограничения соозначивания на
все соответствующие (друг другу) элементы кортежей этих высказываний. Это эквивалентно
унификации двух атомарных формул. Можно ограничить два возможно-несоозначенных
высказывания, чтобы они стали необходимо-несоозначеными посредством наложения
ограничения несоозначивания на любую пару соответствующих (друг другу) элементов
этих высказываний. Например, (on A, x) и (on A, y) можно сделать необходимо-соозначенными,
наложив ограничение соозначивания на x и y, и необходимо-несоозначенными, наложив
ограничение несоозначивания на x и y.
В TWEAK состояния мира именуются ситуациями (situation),
которые представляют собой множества высказываний. Выделяют начальную ситуацию
(initial situation) и конечную ситуацию (final situation) плана. Входной
ситуацией шага (input situation) называется множество высказываний, истинных
непосредственно перед выполнением шага. Аналогично, выходная ситуация
шага (output situation) - множество высказываний, истинных непосредственно после
выполнения шага. В завершенном плане входная ситуация каждого шага является
выходной ситуацией шага предыдущего.
Высказывание истинно в ситуации, если оно соозначено с высказыванием,
являющимся членом ситуации. Шаг утверждает (assert) высказывание, если это высказывание
соозначено с постусловием шага. Высказывание отвергается (denied) в ситуации,
если в этой ситуации утверждается его отрицание. Высказывание не может быть
утверждено и отвержено в одной и той же ситуации.
Теперь можно сформулировать критерий модальной истинности.
Modal Truth Criterion. A
proposition p is necessarily true in a situation s
iff two conditions hold: there is a situation t equal
or necessarily previous to s in which p
is necessarily asserted; and for every step C possibly
before s and every proposition q possibly
codesignating with p which C denies,
there is a step W necessarily between C
and s which asserts r, a proposition
such that r and p codesignate whenever
p and q codesignate. The criterion for
possible truth is exactly analogous, with all the modalities switched
(read "necessarily" for "possible" and vice versa).
|
Критерий модальной истинности.
Высказывание p необходимо истинно в ситуации s,
если и только если выполняются следующие условия:
- Существует ситуация t совпадающая с s
или необходимо предшествующая ей, в которой p необходимо
утверждается.
- Для каждого шага C возможно-предшествующего s
и каждого высказывания q возможно-соозначиваемого с p
такого, что C отвергает q, существует
некоторый шаг W, необходимо находящийся между C
и s, утверждающий высказывание r так,
что r и p соозначены всякий раз, когда
p и q соозначены.
Критерий для возможной истинности аналогичен, если поменять все модальности
(читать "необходимо" вместо "возможно" и наоборот).
|
За сложностью формального определения кроются довольно простые
вещи. А именно, высказывание может быть истинно в ситуации s, если соблюдается
хотя бы одно условие:
- либо высказывание утверждается шагом, выходной ситуацией которого является
s;
- либо высказывание утверждается ранее в ситуации t, и для всякого шага между
t и s, способного отвергнуть высказывание, должен быть шаг, который вновь восстановит
его истинность до наступления ситуации s.
Это можно продемонстрировать следующим рисунком.
Здесь овалами изображены ситуации, а прямоугольниками - шаги.
Сплошные стрелки показывают необходимый временной порядок, а штриховые стрелки
- возможный временной порядок. Прямоугольник из штриховых линий обозначает недопустимый
шаг (C). Прямоугольник нарисованный пунктирной линией символизирует шаг (W),
который делает штриховой шаг допустимым. Шаги вида C Чепмен называет разрушителями
(clobberer), а шаги вида W - белыми рыцарями (white knight).
Критерий модальной истинности можно интерпретировать в процедурном
аспекте. Т.к. критерий формулирует способ достижения необходимой истинности
высказывания, его можно использовать для определения способа достижения цели
(определения необходимой истинности цели). Критерий предлагает несколько альтернативных
путей достижения цели.
В соответствии с критерием цель может быть либо утверждена
(establishment), либо достигнута путем снятия угрозы (declobbering).
Утверждение может потребовать добавления шага (для получения ситуации t), либо
использовать уже имеющуюся ситуацию t. При этом t должна предшествовать либо
совпадать с s и в ней должно достигаться p (или более обще, p должно быть необходимо
истинным). В случае ликвидации угрозы возможны следующие варианты решения проблемы.
Либо нужно обеспечить условие s < С (s предшествует C). Этот прием называется
повышение (promotion) или продвижение. Либо нужно применить симметричный
этому прием - понижение (demotion) - обеспечение условия C < t.
Либо необходимо обеспечить условие q <> p (q несоозначено с p). Такое
ограничение называется разделение (separation). В противном случае
мы сталкиваемся с ситуацией, когда необходимо использовать белого рыцаря. Для
этого нужно добавить новый шаг или использовать имеющийся и наложить соответствующие
ограничения (C < W, W < s, ($r) (p=q —>
p=r)) (здесь знак равенства символизирует соозначивание).
Эти альтернативные пути достижения цели называются операциями
модификации плана (plan modification operations). Их можно отразить на
следующей диаграмме, показывающей способ достижения истинности высказывания
(операции модификации обозначены мелким шрифтом).
На этой диаграмме в явном виде не представлено понижение, т.к.
понижение является частным случаем разрешения угрозы посредством белого рыцаря,
а именно, когда t является выходной ситуацией шага W.
Процедура достижения цели, о которой говорилось ранее, проверяет
все эти пути в поисках способа сделать заданное целевое высказывание истинным.
Пути с добавлением шагов (для создания новой ситуации t или нового шага W) проверяются
в последнюю очередь, чтобы избежать порождения излишне длинных планов.
Подводя итог, отметим, что Чепмен в своей работе приводит не
только алгоритм планировщика, допускающего частичный порядок шагов, но также
формальные доказательства его полноты и корректности. Он вводит приемы модификации
плана и дает им названия ("повышение", "понижение" и "разделение"),
которые в дальнейшем стали широко использоваться в планировании. После TWEAK
появился целый ряд работ, рассматривающих процесс составления плана, как процесс
наложения ограничений.
1991г. — SNLP
Планировщик SNLP примечателен своей простотой как в плане формализации,
так и в отношении самого алгоритма. Основан на методологии формирования частичных
планов. Результаты опубликованы в статье [McAllester,
Rosenblitt, 1991]. Полный перевод статьи см. здесь.
Составление подробного отчета будет выполнено позднее.
1991г. — O-PLAN
[Currie, Tate, 1991]
1992г. — UCPOP
1992г. — SATPLAN
В 1992 году Генри Каутцем (Henry Kautz) и Бартом Селманом (Bart Selman) был предложен принципиально иной подход к задаче планирования [Kautz, Selman, 1992]. Идея заключалась в следующем. Сначала задача планирования формулируется в виде множества ограничений, выраженных логическими формулами. Ограничения накладываются таким образом, чтобы всякая модель этого множества формул соответствовала корректному плану. Затем находится модель для получившегося множества формул и уже из модели извлекается готовый план.
Логические формулы, посредством которых представляется задача планирования в SATPLAN, формулируются несколько иначе, чем в системе QA3 или ситуационном исчислении (хотя и имеется определенное сходство). Вместо понятия состояние (или ситуация) вводится понятие момент времени (instant). По своей сути состояние и момент времени являются одним и тем же. Новый термин был введен для того, чтобы обозначить различие в следующем аспекте: возможных состояний может быть очень много (ситуаций — бесконечное количество), в то время как количество рассматриваемых моментов времени невелико и сопоставимо с количеством действий в плане. Время считается целочисленным и дискретным, отсчет ведется от нуля до некоторой, наперед заданной величины N, которая подбирается в процессе поиска решения. Таким образом, планы длиннее, чем N-1 действий, не рассматриваются.
В такой формализации факты о мире выражаются при помощи высказываний, ссылающихся на момент времени. По аналогии с ситуационным исчислением их называют флюентами (fluent). Например, указание того, что в момент времени 5 кубик A находится на кубике B, можно записать в виде высказывания on(A, B, 5). Начальное состояние соответствует нулевому моменту времени, а конечное — N-ому.
Действия также представляются в виде высказываний (в отличие от ситуационного исчисления!). Например, действие установки кубика A на кубик B в промежуток времени между моментами 4 и 5 можно записать следующим образом: stack(A, B, 4).
Рассмотрим теперь, каково должно быть множество формул (ограничений), чтобы всякая модель этого множества соответствовала плану. Иными словами, определим, как выглядит задача планирования в новой формулировке.
Во-первых, если в плане присутствует действие, выполняющееся между моментами 4 и 5, то это предполагает выполнение следующих условий:
- в момент 4 должны быть истинны предусловия действия,
- в момент 5 должны проявиться эффекты действия.
Такие требования можно записывать при помощи обобщенных формул вида:
- "x,y,i.stack(x,y,i) ® clear(y,i) & holding(x,i)
- "x,y,i.stack(x,y,i) ® on(x,y,i+1) & arm-empty(i+1) & clear(x,i+1) & ¬clear(y,i+1) & ¬holding(x,i+1)
Здесь первая формула описывает предусловия действия stack (установка кубика x на кубик y). Для установки кубика на кубик необходимо, чтобы "кубик, на который устанавливают" был свободен (clear), а "кубик, который устанавливают" был в манипуляторе робота (holding). Вторая формула описывает эффект действия stack. Эффект состоит в том, что кубик x теперь находится на кубике y (on), манипулятор робота свободен (arm-empty), кубик x не занят (clear), кубик y теперь занят (¬clear) (на нем стоит кубик x) и манипулятор робота теперь не держит кубик x (¬holding). Все предусловия должны быть истинны в момент, непосредственно предшествующий выполнению действия (i), а эффекты проявляются в момент, непосредственно следующий за выполнением действия (i+1).
Во-вторых, следует формализовать утверждение о том, что если действие, выполняющееся на интервале (i, i+1), не влияет на какой-либо факт, присутствовавший в момент i, то этот факт останется неизменным и в момент i+1. Или, другими словами, требуется формализовать, какие флюенты останутся неизменными после выполнения конкретного действия. Такие ограничения называются аксиомами фрейма (frame axiom) и могут быть записаны, например, следующим образом.
- "x,y,z,i.(x ≠ y) & (x ≠ z) & clear(x,i) & stack(y,z,i) ® clear(x,i+1)
- "x,y,z,i.(x ≠ y) & (x ≠ z) & ¬clear(x,i) & stack(y,z,i) ® ¬clear(x,i+1)
и т.д. для всех действий и неизменяющихся флюент. Данная пара аксиом утверждает, что после выполнения действия "установка кубика x на кубик y" свойство незанятости (clear) всех прочих кубиков (отличных от x и y) останется неизменным.
В-третьих, необходимо формализовать требование, что только одно действие происходит в один момент времени. Обычно это записывается в виде набора формул, постулирующих, что никакая пара различных действий не может выполняться в один и тот же момент времени. Примером такого рода формул могут послужить следующие:
-
"x,y,i.(x ≠ y) ® (¬pickup(x,i) v ¬pickup(y,i)),
- "x,y,i.¬pickup(x,i) v ¬putdown(y,i),
и т.д. Если в рассматриваемой предметной области количество схем действий равно S, то потребуется S2 таких формул.
В-четвертых, формализуем требование, что в каждый момент времени происходит какое-либо действие. Это можно записать посредством формулы следующего вида.
- "i.( ($x.(pickup(x,i) v putdown(x,i))) v ($x,y.(stack(x,y,i) v unstack(x,y,i))) )
В этой формуле должны быть перечислены все схемы действий рассматриваемой предметной области.
И, наконец, в-пятых, зададим целевое условие и начальное состояние. Целевое условие задается формулой с явным указанием момента времени, когда эта формула должна стать истинной. Например, в предметной области с кубиками цель может быть такой:
on(A,B,2) & on(B,C,2).
Начальное состояние должно задаваться полностью, т.е. постулируется не только истинность, но и ложность фактов. Фактически, это конъюнкция из всех возможных в данном домене фактов; при этом часть фактов (ложных в начальном состоянии) входят в конъюнкцию под операцией отрицания. Все факты начального состояния помечаются нулевым моментом времени.
Всякая модель вышеприведенного множества формул соответствует корректному плану. Это так, потому что каждая модель содержит последовательность действий, предусловия которых выполняются, и выполнение действия в какой-либо момент времени полностью определяет истинностные значения всех фактов в следующий момент.
Такая формулировка задачи планирования обладает рядом привлекательных свойств. Например, становится возможным наложение ограничений не только на начальное и целевое состояния, но и на любое промежуточное состояние, а также на структуру плана. Например, можно потребовать наличия определенного факта в промежуточном состоянии:
on(A,Table,6).
Или требовать наличия в плане определенных действий:
unstack(C,B,0).
Или даже задавать эвристические правила, например:
"i.$x.(pickup(x,i) ® $y.stack(x,y,i+1)).
Это правило гласит, что если кубик был поднят со стола, то в следующий момент он должен быть установлен на какой-нибудь кубик (а не поставлен, например, обратно на стол). Еще одним достоинством такой формулировки является то, что в ней легко и естественно могут быть сформулированы сложные цели в рамках логики предикатов. Например, дизъюнктивные цели или цели с кванторами.
Следует отметить, что приведенная выше формализация ограничений, которым соответствует корректный план, не является единственной. Были разработаны и опробованы другие способы кодирования задачи планирования [Kautz et al., 1996][Kautz, Selman, 1996]. Некоторые из них допускают возможность параллельного исполнения действий.
Рассмотрим теперь, как выполняется поиск плана. В первую очередь выбирается подходящее значение для максимального, принимаемого в рассмотрение момента времени — N. Как уже упоминалось, переменные "момента времени" принимают значения от нуля до некоторого, наперед заданного значения N. Величина N должна соответствовать длине плана, но заранее она, как правило, не известна. Поэтому в процессе поиска плана перебираются различные (разумные) значения для N, пока не будет найдено решение. Например, подбор N можно выполнять инкрементально или экспоненциально.
После того, как очередное N зафиксировано, выполняется трансляция приведенной выше кодировки задачи планирования в логику высказываний. Т.е. выполняется означивание (инстанциация) всех переменных во всех формулах всеми возможными способами. Переменные "момента времени" принимают, соответственно, значения от нуля до зафиксированной N. Атомарные высказывания целевой формулы помечаются N-ым моментом времени. После означивания все формулы приводятся к конъюнктивной нормальной форме.
Следующим шагом является поиск модели для получившегося множества формул логики высказываний, т.е. задача планирования теперь сведена к SAT-задаче. Существует множество алгоритмов решения этой задачи, как переборных (например, DPLL и tableau), так и эвристических (например, GSAT и WalkSAT). Авторы SATPLAN опробовали различные подходы. В ходе экспериментов выяснилось, что ни один из алгоритмов не является более предпочтительным, все зависит от рассматриваемой предметной области.
Алгоритмы поиска модели для множества формул логики высказываний отыскивают такое присваивание истинностных значений атомарным высказываниям, входящим в формулы, при котором все формулы становятся истинными. В процессе поиска литералы, описывающие начальное состояние и целевое условие, должны оставаться истинными.
Если модель обнаруживается, то из нее извлекается план. Это происходит следующим образом. Сначала в модели отыскиваются все атомарные высказывания, соответствующие действиям и имеющие значение "истина". Затем эти действия упорядочиваются в порядке возрастания момента времени.
Формально, алгоритм SATPLAN можно представить следующим образом.
function SATPLAN(problem, maxN)
for N := 0 to maxN
1. Преобразуем problem во множество формул логики высказываний с учетом текущего N.
2. Приведем формулы к конъюнктивной нормальной форме.
3. Запускаем какой-либо алгоритм решения SAT-задачи на получившемся множестве
означенных формул.
4. if (модель найдена) then
4.1. Извлекаем план — ищем в получившейся модели все атомарные высказывания,
соответствующие действиям и имеющие значение "истина".
4.2. return (извлеченный план).
end-for
return "план не найден".
|
Из описания алгоритма видно, что планировщик всегда находит план минимальной длины.
Основным недостатком такого подхода является огромное количество и большие размеры формул, получающихся в результате кодирования задачи планирования в SAT-задачу. Размер SAT-задачи можно сократить путем применения более изощренных методов кодирования. Например, можно все k-арные предикаты, используемые для описания действий, свести к наборам бинарных предикатов (авторы назвали этот прием "разделением операторов", operator splitting).
Алгоритм способен справляться с большими задачами в сложных (переборных) предметных областях.
1993г. — BURIDAN
В 1990-95 годах происходит всплеск развития вероятностных
планировщиков (probabilistic planners). В отличие от классических планировщиков,
предполагающих детерминистичность поведения и точные знания о мире, вероятностные
планировщики адаптированы для рассуждений в средах с неопределенностью. Одной
из наиболее известных работ (того времени) в этом направлении является планировщик
BURIDAN. Он разработан коллективом авторов в составе Николаса Кушмерика (Nicholas
Kushmerick), Стива Хэнкса (Steve Hanks) и Даниеля Уэлда (Daniel Weld).
Основные результаты опубликованы в работе [Kushmerick
et al., 1994] (см. также более подробную версию [Kushmerick
et al., 1994]).
В BURIDAN источниками неопределенности являются неточные знания
о начальном состоянии и эффектах действий. Вместо классического начального состояния
в постановке задачи планирования фигурирует распределение
вероятностей на множестве возможных начальных состояний. Кроме того, эффекты
действий зависят от случайных факторов (вероятности проявления того или иного
эффекта задаются в описании схем действий). Использование вероятностной модели
усложняет также определение корректного плана. Вместо классического "плана,
достигающего цель", используется "план, достигающий цель с вероятностью
выше заданного порога".
Алгоритм BURIDAN основан на алгоритме SNLP и является полным и корректным.
Авторам BURIDAN пришлось разработать
новый формализм описания домена и задачи планирования для того, чтобы включить
упомянутые факторы неопределенности в модель рассуждений. Рассмотрим новые
определения и новые понятия, необходимые для постановки задачи в BURIDAN.
Состояния и неопределенность.
Состояние - это формальное описание
мира в определенный момент времени. Состояние определяется как множество
различных высказываний о мире (выраженных, например, означенными предикатами).
Неопределенность задается при помощи случайной
величины на множестве возможных состояний. Обозначим sI случайную
величину, принимающую значения на множестве возможных начальных состояний.
Пусть модель предметной области состоит из трех фактов (F1, F2 и F3) и
известно, что в начальном состоянии факты F2 и F3 присутствуют, а факт F1 присутствует
с вероятностью 0.8. Тогда множество возможных начальных состояний содержит
два элемента (состояния): s1 = (F1, F2, F3) и s2 = (F2,
F3). В этом случае распределение вероятностей можно задать следующим образом:
P[sI=s1]
= 0.8, P[sI=s2] = 0.2.
Действия и неопределенность.
Описание действия сочетает в себе символьную модель для обозначения
эффектов действий и вероятностные параметры для моделирования факторов неопределенности.
В качестве примера, рассмотрим действие "найти предмет" и определим
его следующим образом. Если "в комнате горит свет", то действие дает
эффект
"предмет найден" с вероятностью 0.9 (не найден, соответственно, с
вероятностью 0.1). Если же "свет в комнате не горит", то действие
дает эффект "предмет найден"
с вероятностью лишь 0.15 (не найден, соответственно, с вероятностью 0.85).
Такое описание подобно условным эффектам из UCPOP, но здесь мы имеем дело еще
и с вероятностными коэффициентами. Данное действие можно представить графически
следующим образом.
Формально, в BURIDAN действие - это множество заключений (consequence)
вида:
{‹ta, pa, ea›,...,‹tn,
pn, en›}
, где ti - выражение, называемое триггером заключения, pi -
вероятность, а ei - эффект (множество литералов). Рассмотрим формальную
запись действия "найти предмет". Для краткости обозначим высказывание "горит
свет" символом LO, а высказывание "предмет найден" - OF. Тогда формальная запись
действия "найти предмет" будет выглядеть следующим образом:
{‹LO, 0.9, {OF}›, ‹LO, 0.1, {}›, ‹¬LO, 0.15, {OF}›, ‹¬LO, 0.85,
{}›}.
Каждое отдельное заключение подобно классическому действию (предусловие
(триггер) + эффект), т.е. обозначает переход от состояния к состоянию. Действие
в целом вызывает переход от состояния к распределению вероятностей на множестве
всех возможных состояний. Вероятность каждого отдельного состояния s' определяется
формулой.
Из формулы видно, что вероятность проявления эффекта зависит
от вероятности наличия триггера в состоянии s и вероятности проявления эффекта
по этому триггеру. Сумма вероятностей P[s'|s,A] по всем s' равна единице.
Последовательности действий.
Вероятность состояния s' после выполнения последовательности
действий ‹A1,...,AN› применительно к некоторому
начальному состоянию s определяется следующим образом:
Выражения и цель.
Выражение представляется как
множество (а трактуется как конъюнкция) литералов. Цель планирования в BURIDAN
задается выражением.
Введем понятие вероятности выражения E по отношению к
состоянию s. Величина этой вероятности определяется по формуле:
Вероятность того, что выражение E будет истинным, если
к состоянию s будет применена последовательность действий ‹A1,...,AN› определяется
формулой.
Если вместо s рассматривать распределение вероятностей на множестве
начальных состояний sI, то получим формулу для вероятности достижения цели E данной
последовательностью действий ‹A1,...,AN›.
Задача планирования и решение.
Задача планирования состоит из:
- распределения вероятностей на множестве возможных начальных состояний;
- множества возможных действий;
- целевого выражения G;
- порога T.
Решением задачи планирования является такая последовательность
действий ‹A1,...,AN›,
что P[G | sI, ‹A1,...,AN›] ≥ T.
Алгоритм.
Как уже упоминалось, BURIDAN основан на алгоритме SNLP, т.е.
поиск ведется в пространстве частичных планов. Поиск начинается от пустого плана
(null plan), который содержит лишь два действия-заглушки A0 и AG,
а также одно упорядочивающее ограничение (A0<AG).
Действие A0 содержит по одному заключению для каждого из возможных
начальных состояний (с ненулевой вероятностью). Все триггеры A0 пусты,
а эффекты и их вероятности соответствуют возможным начальным состояниям и их
вероятностям. Действие AG содержит одно заключение с триггером G.
Начиная с пустого плана, BURIDAN осуществляет две операции:
- Оценку стоимости плана. На этом этапе проверяется,
превышает ли вероятность того, что текущий план достигает цель, заданный
порог T. Если это так, то работа алгоритма завершается и возвращается
план. Этот шаг сложен в вычислительном аспекте. Было разработано несколько
стратегий для оценки, каждая из которых выгодна в одних случаях и неэффективна
в других.
- Уточнение плана. Выполняется попытка увеличить вероятность
достижения цели путем уточнения (ликвидации угрозы или добавления причинной
связи, увеличивающей вероятность). В случае добавления причинной связи все
аналогично SNLP. Однако для ликвидации угрозы, кроме обычных
повышения (promotion) и понижения (demotion), используется дополнительный способ
разрешения угроз - конфронтация (confrontation). Суть конфронтации заключается
в том, чтобы сделать невозможным выбор заключений (действия), представляющих
угрозу. Точнее выбираются только те заключения, которые не представляют угрозы,
а триггеры этих заключений становятся подцелями. Подобный прием использовался
и в UCPOP для условных эффектов.
Алгоритм BURIDAN написан на Common Lisp.
1995г. — Graphplan
См. обзор по Graphplan.
Современные направления исследований
Библиография.
| [Newell et al., 1959] |
Newell A., Shaw J. C., Simon H. A., Report
on a general problem-solving program. IFIP Congress, 1959, стр. 256-264. |
| [Green C., 1969a] |
Green C., The Application of Theorem Proving
to Question-Answering System. Garland Publishing, New York, 1969. |
| [Green C., 1969b] |
Green C., Application of Theorem Proving to Problem
Solving. IJCAI'69, 1969, стр. 219-240. |
| [Fikes, Nilsson, 1971] |
Fikes R.E., Nilsson N.J., STRIPS: A New Approach
to the Application of Theorem Proving to Problem Solving. IJCAI'71,
стр. 608-620. |
| [Fikes, Hart, Nilsson, 1972] |
Fikes R.E., Hart P.E., Nilsson N.J., Learning
and Executing Generalized Robot Plans. Artificial Intelligence, том
3, 1972, стр. 251-288. |
| [Sussman G.J., 1973] |
Sussman G.J., A Computational Model of Skill
Acquisition. MIT AI Tech. Report №297, Cambridge, MA, 1973. |
| [Tate A., 1974] |
Tate A., Interacting Goals in Problem Solving.
AISB Newsletter, 18, 1974, стр. 31-38. |
| [Tate A., 1975] |
Tate A., Interacting Goals and their Use.
IJCAI'75, 1975, стр. 215-218. |
| [Sacerdoti E.D., 1974] |
Sacerdoti E.D., Planning in a Hierarchy of Abstraction
Spaces. Artificial Intelligence, том 5, 1974, стр. 115-135 |
| [Warren D., 1974] |
Warren D.H.D., WARPLAN: A System for Generating
Plans. Departament of Computational Logic Memo №76, University of
Edinburgh, 1974. |
| [Sacerdoti E.D., 1975] |
Sacerdoti E.D., The Non-Linear Nature of Plans.
IJCAI'75, 1975, стр. 206-214. |
| [Sacerdoti E.D., 1977] |
Sacerdoti E.D., A Structure for Plans and Behaviour.
Elsevier North-Holland, New York, 1977. |
| [Tate A., 1976] |
Tate A., Project Planning Using a Hierarchic Non-linear
Planner. University of Edinburgh, D.A.I. Research Report № 25, 1976. |
| [Tate A., 1977] |
Tate A., Generating Project Networks. IJCAI'77,
1977, стр. 888-893. |
| [Wilkins D.E., 1983] |
Wilkins D.E., Representation in a Domain-Independent
Planner. IJCAI'83, 1983, стр. 733-740. |
| [Wilkins D.E., 1984] |
Wilkins D.E., Domain-Independent Planning: Representation
and Plan Generation. Artificial Intelligence, том 22, № 3, 1984,
стр. 269-301. |
| [Chapman D., 1987] |
Chapman D., Planning for Conjunctive Goals.
Artificial Intelligence, том 32, №3, 1987, стр. 333-377. |
| [McAllester, Rosenblitt, 1991] |
McAllester D.A., Rosenblitt D., Systematic Nonlinear
Planning. AAAI'91, 1991, стр. 634-639. |
| [Currie, Tate, 1991] |
Currie K., Tate A., O-Plan: The Open Planning
Architecture. Artificial Intelligence, том 52, № 1, 1991, стр.
49-86. |
| [Kushmerick et al., 1994] |
Kushmerick N., Hanks S., Weld D.S., An
Algorithm for Probabilistic Least-Commitment Planning. AAAI'94,
1994, стр.
1073-1078. |
| [Kushmerick et al., 1994] |
Kushmerick N., Hanks S., Weld D.S., An
Algorithm for Probabilistic Planning. Technical Report 93-06-03,
Departament of Computer Science and Engineering, University of Washington,
1994. |
| [Kautz, Selman, 1992] |
Kautz H., Selman B., Planning as Satisfiability. ECAI'92, 1992, стр. 359-363. |
| [Kautz, Selman, 1996] |
Kautz H., Selman B., Pushing the Envelope: Planning, Propositional Logic, and Stochastic Search. AAAI/IAAI'96, том 2, 1996, стр. 1194-1201. |
| [Kautz et al., 1996] |
Kautz H., McAllester D., Selman B., Encoding Plans in Propositional Logic. KR-96, 1996, стр. 374-384. |
Трофимов И.В.
апрель 2005 - март 2006